[論文レビュー] Collaborating with language models for embodied reasoning
本論文は、事前学習済み言語モデルと具現化されたRLエージェントを組み合わせた Planner-Actor-Reporter アーキテクチャを提案し、2Dグリッド世界での多段推論と情報収集を行い、ゼロショット一般化と協調強化学習によるレポーティングを示す。
Reasoning in a complex and ambiguous environment is a key goal for Reinforcement Learning (RL) agents. While some sophisticated RL agents can successfully solve difficult tasks, they require a large amount of training data and often struggle to generalize to new unseen environments and new tasks. On the other hand, Large Scale Language Models (LSLMs) have exhibited strong reasoning ability and the ability to to adapt to new tasks through in-context learning. However, LSLMs do not inherently have the ability to interrogate or intervene on the environment. In this work, we investigate how to combine these complementary abilities in a single system consisting of three parts: a Planner, an Actor, and a Reporter. The Planner is a pre-trained language model that can issue commands to a simple embodied agent (the Actor), while the Reporter communicates with the Planner to inform its next command. We present a set of tasks that require reasoning, test this system's ability to generalize zero-shot and investigate failure cases, and demonstrate how components of this system can be trained with reinforcement-learning to improve performance.
研究の動機と目的
- 事前学習済み言語モデルが planner(自然言語指示を具象エージェントへ出す)として機能する方法を示す。
- Reporter が Actor の観測を Planner に翻訳し、指示の洗練のための閉ループを形成することを示す。
- モデルサイズとタスク変種に対するプランナーのゼロショット一般化と頑健性を評価する。
- 協調を改善し手作りフィードバックを減らすための Reporter の強化学習による訓練を調査する。
- 不完全なレポート下でのシステムの故障モードと頑健性を分析する。
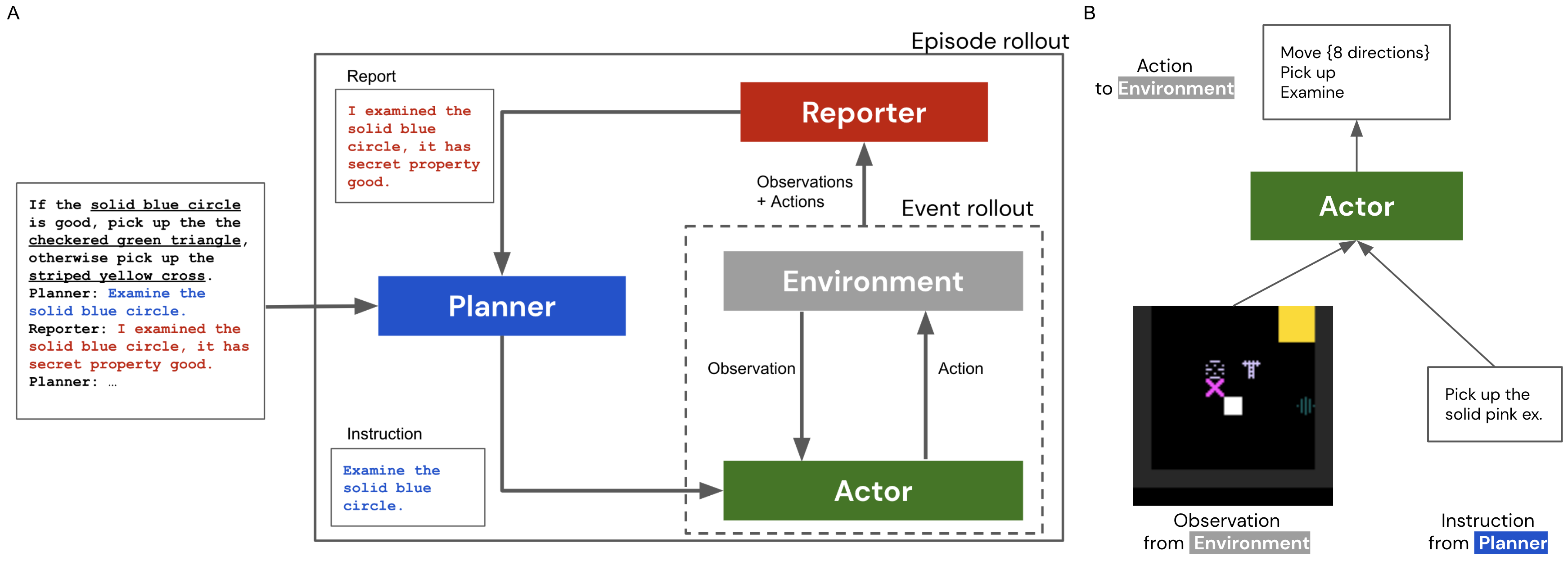
提案手法
- 三部構成システムを実装する:Planner(LSLM)、Actor(RLエージェント)、Reporter(ActorデータをPlannerへ翻訳する。)、
- 7Bおよび70BパラメータのChinchillaベースLLMをPlannersとしてfew-shot promptsと共に使用する。
- Actorはシンプルなピックアップおよび検査タスクで訓練する。観察者は環境内のReporterを用いて指示をフィードバックする。
- 色・形・質感で区別されるオブジェクトを持つ2D部分観測グリッド世界を定義し、検査および拾取アクションを許可する。
- 情報収集とレポートされた特性に基づく条件判断を要する秘密属性タスクを実験する。
- 完璧ではないレポートに対するPlannerの頑健性を評価し、Reportの訓練を強化学習で最適化して報酬を高める可能性を探る。
実験結果
リサーチクエスチョン
- RQ1プランナー-アクター-レポーターシステムは、具象環境における情報収集タスクのゼロショット解法を可能にするか。
- RQ2プランナーサイズ(7B対70B)は、性能とReporterの不完全性に対する頑健性にどのように影響するか。
- RQ3Reportが不完全な場合の主な故障モードは何か、明示的なプロンプティングでそれを緩和できるか。
- RQ4学習済みReporterはRLを通じて性能を改善し、手作りフィードバックへの依存を減らせるか。
- RQ5提案タスクは、具象推論における論理的推論・一般化・探索・知覚をどれだけ効果的に検証できるか。
主な発見
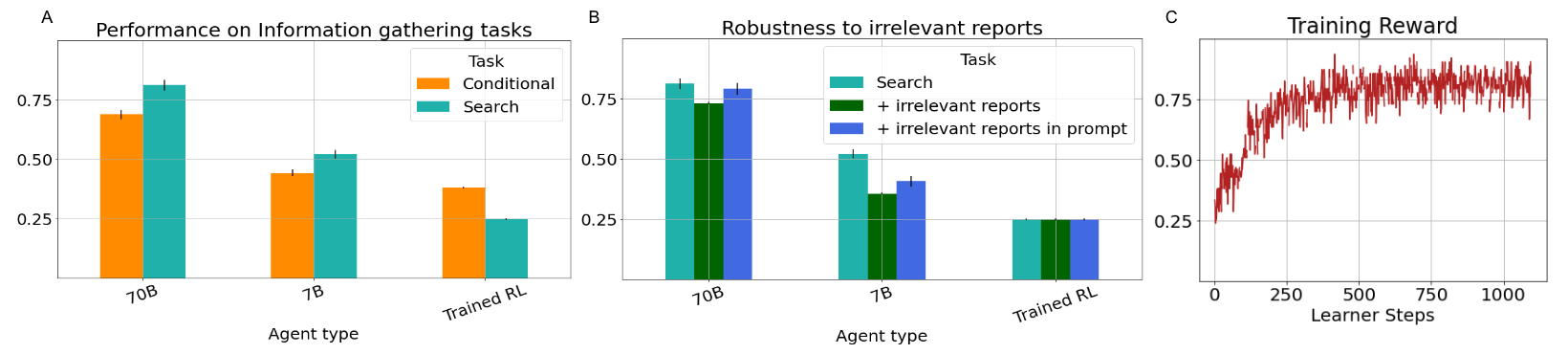
- 70Bプランナーは、情報収集タスクで7Bプランナーより成功率が高い(例:正しい物体を拾う推論の向上など)。
- 純粋なRLベースラインは秘密属性タスクで苦戦する一方、Planner-Actor-Reporterはゼロショットで強い結果を示す。
- プランナーはノイズの多いレポートに対して頑健で、20%が無関係なレポートでも70Bが7Bより性能を維持する。
- Reportsが無関係な場合でも、反復的な戦略を示すプロンプトを提供すると性能を回復できる。
- ReporterをRLで訓練することは実現可能で、タスク成功のために最も有用な情報をプランナーが学習するのに役立つ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。