[論文レビュー] Compact Transformer Tracker with Correlative Masked Modeling
本論文は、訓練時の特徴統合を強化する相関マスク型デコーダを備えたコンパクトなViTベースのトラッカーCTTrackを提案する。40fpsで動作し、最先端に近い性能を達成する一方で、相関デコーダは他のトラッカーへ組み込み可能。
Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.
研究の動機と目的
- ビジュアルトラッキングにおける情報統合のためのバニラ自己注意が十分かを評価する。
- 自己情報の強化がマルチイメージ注意におけるクロス情報統合より支配的であることを示す。
- 推論を遅くせずに、エンコーダを訓練して不変特徴抽出を行う軽量な相関マスクデコーダを開発する。
- 複数のトラッキングベンチマークで最先端に近い性能を示す。
- 速度を損なうことなく、他のトランスフォーマー型トラッカーを改善できる訓練時モジュールを提供する。
提案手法
- テンプレートと探索画像を入力として結合するプレーンなVision Transformerのバックボーンを採用する。
- 自己デコーダとクロスデコーダを備えた相関マスクデコーダを導入し、マスク化トークンからテンプレートと探索画像を再構成する。
- L1、一般化IoU、デコーダ再構成損失(マスク化トークンのMSE)を組み合わせたマルチタスク損失で訓練する。
- トークンのマスキング比率は75%に設定し、表現学習を最大化するようにする(MIMに触発)。
- 推論時にはViTバックボーンとボックスヘッドのみを使用し、デコーダは訓練時のみ使用する。
- 任意でオンラインテンプレートをスコアリングヘッドで更新し、信頼度の高い更新を決定する。
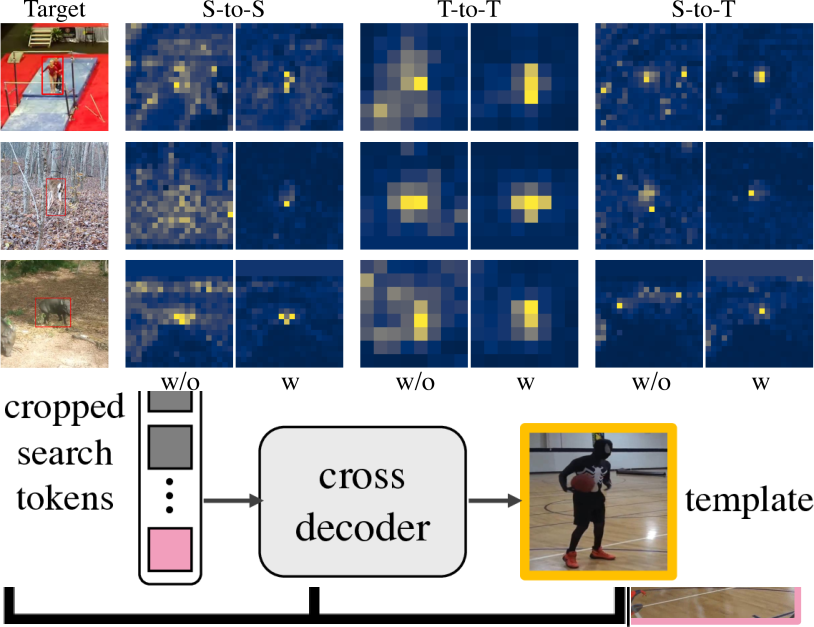
実験結果
リサーチクエスチョン
- RQ1テンプレートと探索を結合した場合、視覚トラッキングにおける情報統合は自己注意で十分か?
- RQ2どの情報ストリーム(テンプレートの自己情報、クロス情報、探索画像の自己情報)がトラッキング性能に最も寄与するか?
- RQ3相関マスクモデリングは推論速度を損なうことなくCTTrackを改善できるか?
- RQ4標準ベンチマークでCTTrackは最先端トラッカーと比較してどの程度の性能か?
主な発見
- 著者らは、トラッキングにおける情報統合にはバニラの自己注意で十分であり、自己情報ストリームの方がクロス情報ストリームより影響力が大きいことを示している。
- CTTrackはViTバックボーンとシンプルなボックスヘッドで40 fpsを実現し、速度と精度の両方で強力。
- LaSOTではCTTrack-LがAUC 69.8%、Prec 76.2%、CTTrack-BがAUC 64.0%、Prec 67.7%のアブレーションで達成。
- ベンチマーク全体でCTTrack-LはUAV123でAUC 71.3%、TrackingNetでAUC 84.9%、GOT-10k AO 72.8%を達成しており、競争力のある最先端性能を示す。
- 相関マスク付きデコーダを取り入れると、LaSOTのアブレーションでCTTrack-LのAUCが65.8%、Precが70.9%へ向上する。
- 相関マスクデコーダは他のトラッカーへ組み込み、推論を遅くすることなく性能を向上させることができる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。