[論文レビュー] Comparative Performance Evaluation of Large Language Models for Extracting Molecular Interactions and Pathway Knowledge
本論文は複数の大規模言語モデル(LLM)を生物医学NLPタスクで系統的に比較する:タンパク質間相互作用、低線量放射によって影響を受ける経路、遺伝子調節関係を対象とし、設定やデータソースごとに最も性能が高いモデルを特定する。
Background: Identification of the interactions and regulatory relations between biomolecules play pivotal roles in understanding complex biological systems and the mechanisms underlying diverse biological functions. However, the collection of such molecular interactions has heavily relied on expert curation in the past, making it labor-intensive and time-consuming. To mitigate these challenges, we propose leveraging the capabilities of large language models (LLMs) to automate genome-scale extraction of this crucial knowledge. Results: In this study, we investigate the efficacy of various LLMs in addressing biological tasks, such as the recognition of protein interactions, identification of genes linked to pathways affected by low-dose radiation, and the delineation of gene regulatory relationships. Overall, the larger models exhibited superior performance, indicating their potential for specific tasks that involve the extraction of complex interactions among genes and proteins. Although these models possessed detailed information for distinct gene and protein groups, they faced challenges in identifying groups with diverse functions and in recognizing highly correlated gene regulatory relationships. Conclusions: By conducting a comprehensive assessment of the state-of-the-art models using well-established molecular interaction and pathway databases, our study reveals that LLMs can identify genes/proteins associated with pathways of interest and predict their interactions to a certain extent. Furthermore, these models can provide important insights, marking a noteworthy stride toward advancing our understanding of biological systems through AI-assisted knowledge discovery.
研究の動機と目的
- 生物医学文献から分子相互作用と経路知識を抽出する多様な大規模言語モデル(LLM)の有効性を評価する。
- 複数のLLMでPPI認識、低線量放射(LDR)影響経路の遺伝子取得、遺伝子調節関係タスクを比較する。
- 特定の生物学的知識抽出タスクにおいて優れているモデルを特定し、制限と機会を議論する。
提案手法
- Galactica、Alpaca、RST、Falcon、MPT、LLaMA2、およびドメイン特化型BioGPT/BioMedLMを含む複数のLLMを3つのbioNLPタスクで評価する。
- データソースとしてSTRING、KEGG、INDRAを用い、PPI、経路遺伝子、遺伝子調節関係の評価セットを構築する。
- タスクごとに最適な prompting 戦略を特定するため、文脈内の例の数(0–5ショット)とプロンプトを変化させる。
- 4× NVIDIA A100 80GB GPUで、タスク固有のバッチサイズで実験を実行する。
- 性能を定量化するためにマイクロF1、マクロF1、完全一致数を報告する。
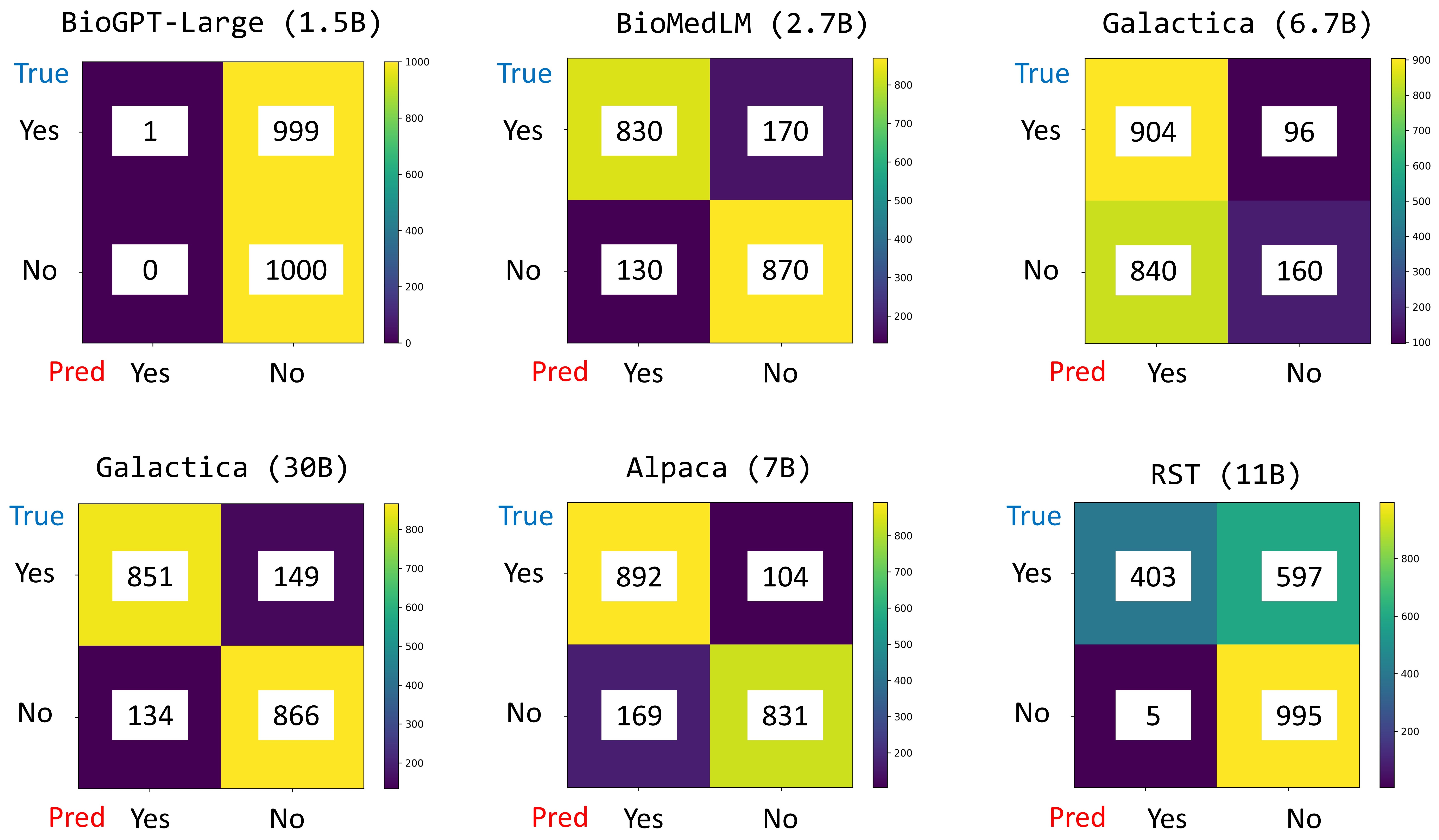
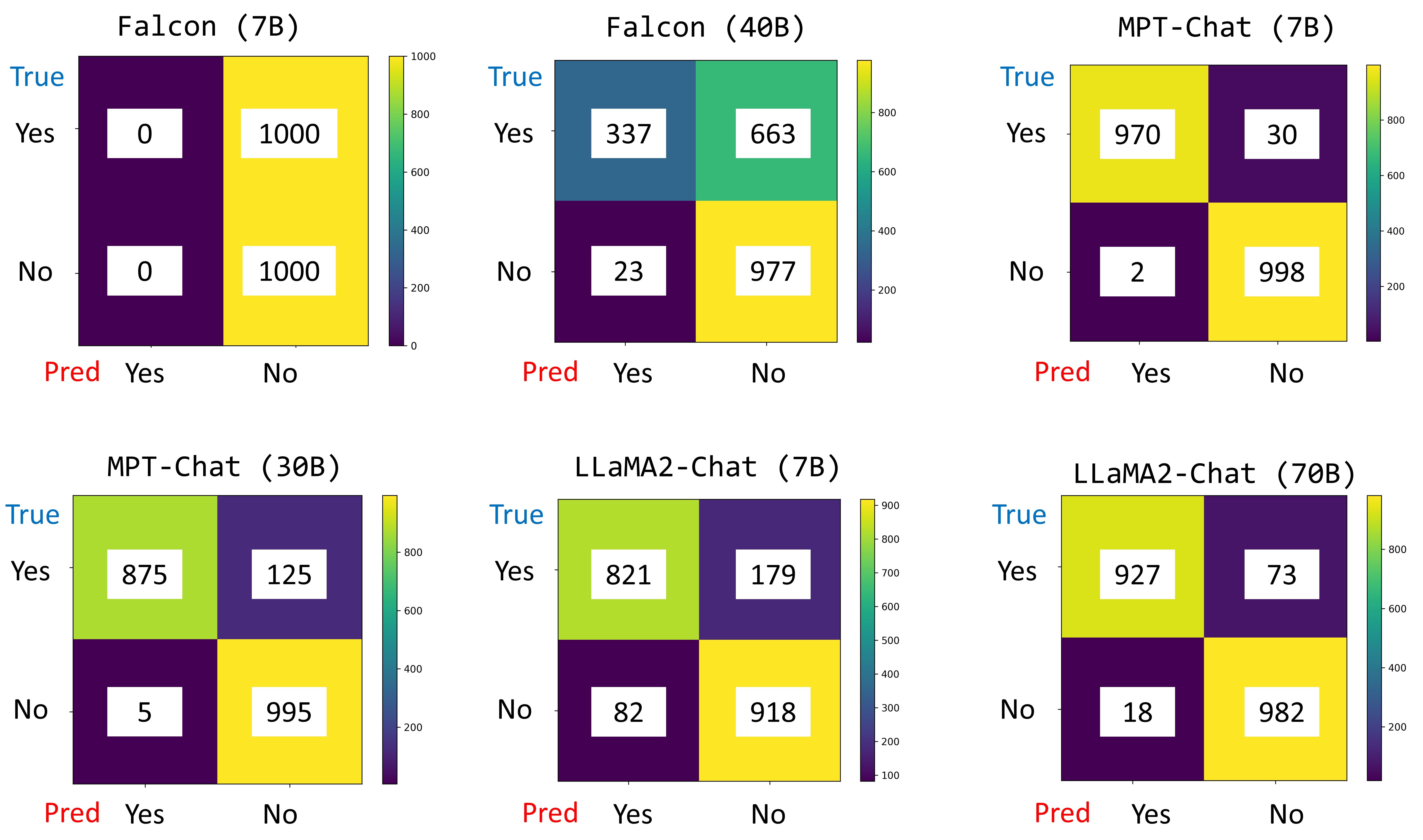
実験結果
リサーチクエスチョン
- RQ1STRING由来の人間タンパク質ネットワークにおいて、どのLLMがタンパク質間相互作用を最もよく認識するか。
- RQ2KEGGデータを用いて、低線量放射影響を受ける人間経路の遺伝子をどのモデルが最も正確に同定するか。
- RQ3INDRA DBのテキスト文から遺伝子調節関係をLLMがどれだけうまく分類できるか。
- RQ4モデルサイズやドメイン特化がタスク間の性能と相関するか。
- RQ5ショット( prompting の戦略) は各タスクの性能にどのように影響するか。
主な発見
| Model | Micro F1 | Macro F1 | # Full Match out of 1K protein list |
|---|---|---|---|
| BioGPT-Large (1.5B) | 0.1220 | 0.1699 | 10 |
| BioMedLM (2.7B) | 0.1584 | 0.1992 | 61 |
| Galactica (6.7B) | 0.2110 | 0.2648 | 75 |
| Galactica (30B) | 0.2867 | 0.3516 | 110 |
| Alpaca (7B) | 0.1573 | 0.2211 | 23 |
| RST (11B) | 0.0987 | 0.1523 | 10 |
| Falcon (7B) | 0.0435 | 0.0632 | 7 |
| Falcon (40B) | 0.1124 | 0.1492 | 31 |
| MPT-Chat (7B) | 0.1307 | 0.1688 | 40 |
| MPT-Chat (30B) | 0.2926 | 0.3467 | 144 |
| LLaMA2-Chat (7B) | 0.2768 | 0.3436 | 99 |
| LLaMA2-Chat (70B) | 0.3517 | 0.4187 | 159 |
- PPI Task1では、LLaMA2-Chat(70B)が最も高いMicro F1とMacro F1を達成し、1K中で159件の完全一致を記録。
- PPI Task1では、LLaMA2-Chat(7B)がMPT-Chat(30B)やGalactica(30B)とほぼ同等の性能を示す。
- PPI Task2(二値YES/NO)では、MPT-Chat(7B)とMPT-Chat(30B)が最も強く、Micro F1はそれぞれ0.9840と0.9350(5-shot)まで到達。
- LDR経路タスクでは、Galactica(30B)とMPT-Chat(30B)が遺伝子を最も正確に予測し、BioMedLMとBioGPT-Largeはドメイン特有データで顕著な向上を示す。
- INDRAタスクでは、Galactica 30B、LLaMA2-Chat 70B、MPT-Chat 30Bなどの大規模モデルが、より小さなBioGPT/BioMedLMモデルを上回り、遺伝子調節関係の読解においてサイズと多様な学習データが有効であることを示す。
- ドメイン特化の小型モデルは、特定の専門タスクでより大きな一般モデルを上回ることがあり、タスクとドメインの整合が重要であることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。