[論文レビュー] Complex Logical Reasoning over Knowledge Graphs using Large Language Models
LARKは、KGクエリを抽象化し、サブグラフを取得し、複雑なクエリを単一操作のプロンプトに分解して逐次的なLLM推論を行うことで、知識グラフ上の論理的推論を大規模言語モデルと統合し、標準的なKGベンチマークで最先端の結果を達成します。
Reasoning over knowledge graphs (KGs) is a challenging task that requires a deep understanding of the complex relationships between entities and the underlying logic of their relations. Current approaches rely on learning geometries to embed entities in vector space for logical query operations, but they suffer from subpar performance on complex queries and dataset-specific representations. In this paper, we propose a novel decoupled approach, Language-guided Abstract Reasoning over Knowledge graphs (LARK), that formulates complex KG reasoning as a combination of contextual KG search and logical query reasoning, to leverage the strengths of graph extraction algorithms and large language models (LLM), respectively. Our experiments demonstrate that the proposed approach outperforms state-of-the-art KG reasoning methods on standard benchmark datasets across several logical query constructs, with significant performance gain for queries of higher complexity. Furthermore, we show that the performance of our approach improves proportionally to the increase in size of the underlying LLM, enabling the integration of the latest advancements in LLMs for logical reasoning over KGs. Our work presents a new direction for addressing the challenges of complex KG reasoning and paves the way for future research in this area.
研究の動機と目的
- 従来の埋め込みベースの手法を超える、大規模でノイズを含み不完全な知識グラフに対する堅牢な推論を動機づける。
- 抽象化とサブグラフコンテキストを用いてKG推論とLLM推論を分離し、シンプルなプロンプトに対してLLMの強みを活用する。
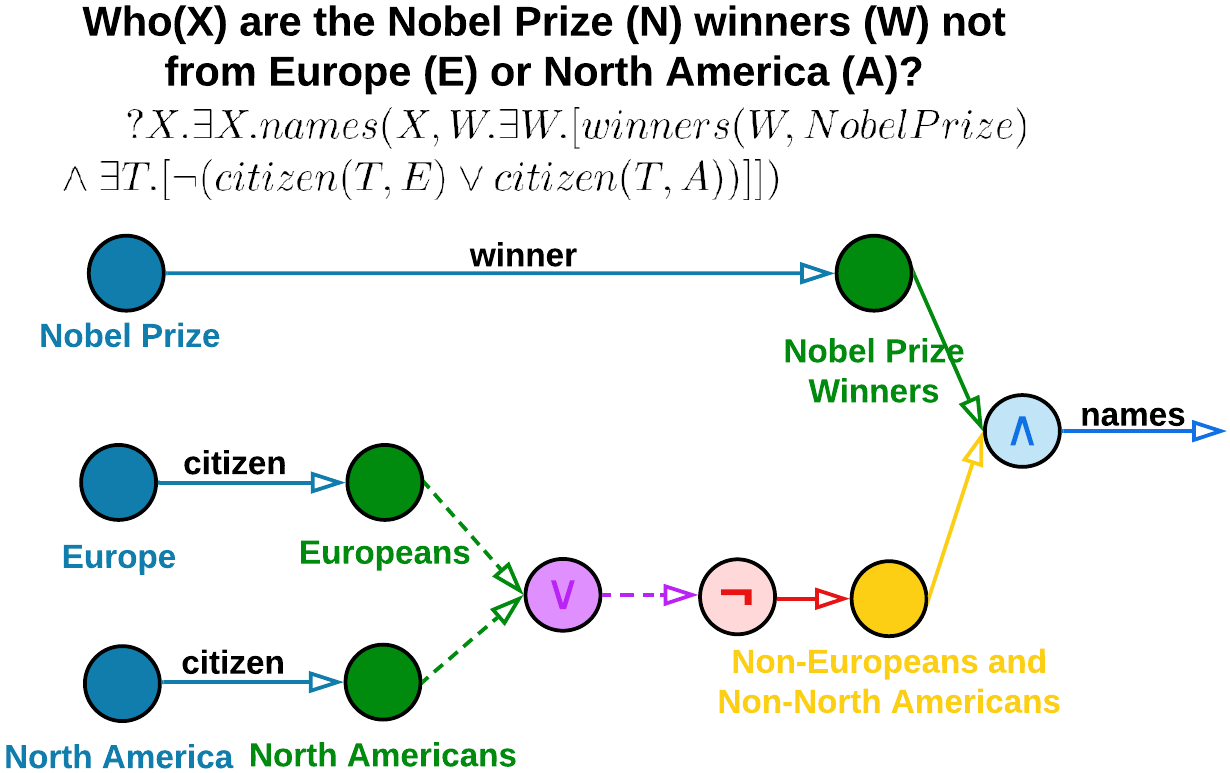
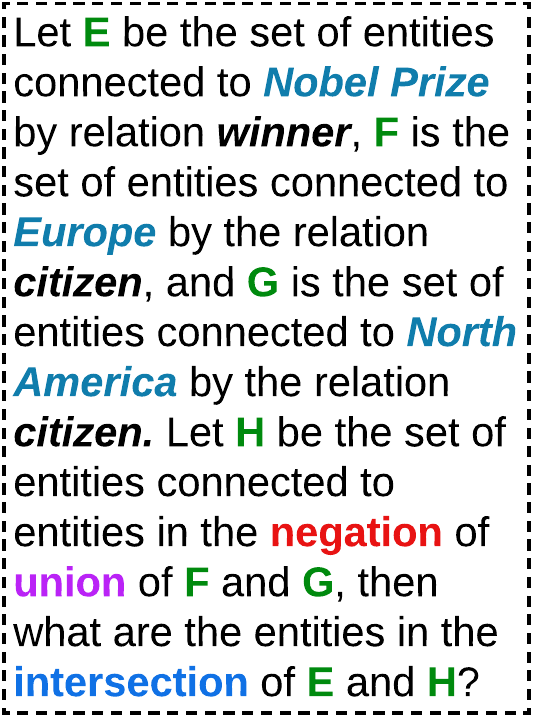
- チェーン分解と論理的に順序付けられたプロンプトによって、複雑な一階述語論理クエリ(p, ∧, ∨, ¬)の性能を向上させる。
- より大きなLLMでのスケーラビリティを示し、クエリ抽象化が一般化と幻覚の低減に与える影響を分析する。
提案手法
- エンティティとリレーションを一意のIDに抽象化し、KG非依存のプロンプトを形成してトークン負荷を低減する。
- クエリエンティティ/リレーションを中心とした文脈サブグラフを構築するためにkレベルの近傍検索を実行する。
- 複雑な多操作クエリを単一操作クエリの連鎖列に分解する(例:3p → 1p連鎖; 投影付きの3i/2i)。
- 分解したクエリと近傍コンテキストを、依存回答のプレースホルダーと過去の結果のメモリ内キャッシュを備えたLLMプロンプトに変換する。
- 論理的に順序付けられたフェーズで分解済みプロンプトを処理し、中間結果のバッチ処理と再利用を可能にしつつ幻覚を最小化する。
- FB15k、FB15k-237、NELL995に対して、ベースライン(GQE、Q2B、BetaE、HQE、HypE、CQD)に対して実証的にLARKを検証する。
実験結果
リサーチクエスチョン
- RQ1LARKは標準的なKG論理推論ベンチマークで最先端のベースラインを上回るか?
- RQ2連鎖分解プロンプトは、LLMベースのKG推論における標準の複雑プロンプトより効果的か?
- RQ3より大きなLLMとトークン容量でLARKの性能はどうスケールするか?
- RQ4クエリ抽象化がデータセット全体での性能と一般化に与える影響は?
- RQ5LARKは否定と複雑なクエリタイプを、従来の手法より効果的に処理できるか?
主な発見
- LARKは、複数のデータセットにわたる14種類のFOLクエリタイプで、33%–64%のMRRの向上を達成し、従来の最先端ベースラインを上回る。
- チェーン分解は複雑なクエリに対して9%–26%の改善をもたらし、LLMの推論を分割する利点を浮き彫りにする。
- LLMサイズの拡大(Flan-T5 L から XXL)により顕著な向上をもたらし、FB15k-237でMRRが最大で118%増加。
- クエリ抽象化はトークン負荷と幻覚リスクを減らし、性能の損失はほとんどない;意味情報が豊富な変種は、トークン制限のため複雑なクエリで性能をわずかに悪化させる可能性がある。
- LARKは否定の取り扱いが強く、否定クエリでしばしばベースラインを上回るが、いくつかのクエリタイプでトークン長の制約に関連する留意点がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。