[論文レビュー] Comprehensive Evaluation of Multimodal AI Models in Medical Imaging Diagnosis: From Data Augmentation to Preference-Based Comparison
この論文はCTケースデータセットを拡張し、一般目的のマルチモーダルモデルを視覚系モデルおよび医師と比較する好みベースの評価を用いて、マルチモーダル医用画像診断の評価フレームワークを提示します。
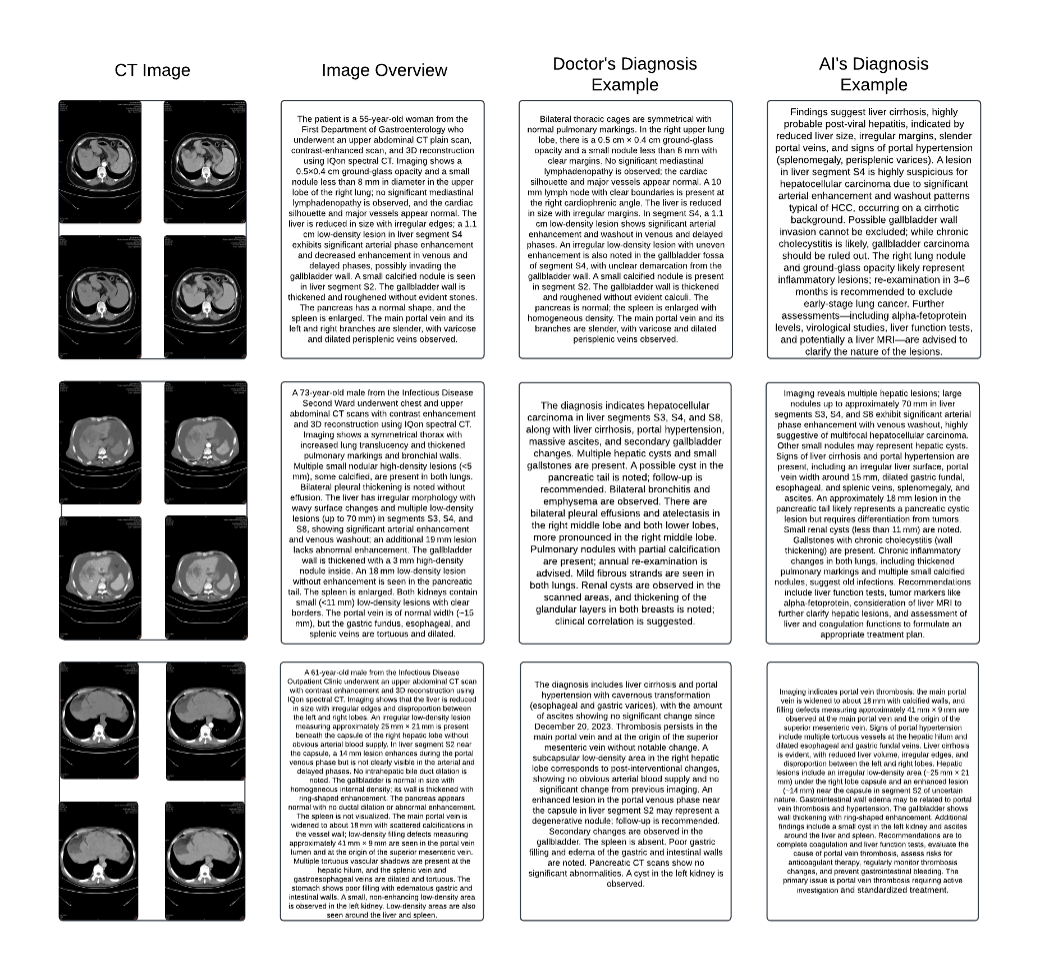
This study introduces an evaluation framework for multimodal models in medical imaging diagnostics. We developed a pipeline incorporating data preprocessing, model inference, and preference-based evaluation, expanding an initial set of 500 clinical cases to 3,000 through controlled augmentation. Our method combined medical images with clinical observations to generate assessments, using Claude 3.5 Sonnet for independent evaluation against physician-authored diagnoses. The results indicated varying performance across models, with Llama 3.2-90B outperforming human diagnoses in 85.27% of cases. In contrast, specialized vision models like BLIP2 and Llava showed preferences in 41.36% and 46.77% of cases, respectively. This framework highlights the potential of large multimodal models to outperform human diagnostics in certain tasks.
研究の動機と目的
- 腹部CT診断におけるマルチモーダルモデルの標準化された評価パイプラインを開発する。
- 堅牢なモデル比較を可能にする臨床データセットを拡張する。
- 好みベースの評価を用いてAIモデルと医師の診断を比較評価する。
- 複雑な診断シナリオにおける一般目的モデルと専門的な視覚モデルを対比する。
提案手法
- 識別情報の除去、アーティファクト処理、画像とテキストの同期的な拡張を含むデータ前処理。
- 診断報告と対になった4-image CTシーケンスを、各モデルの標準入力としてエンコードする。
- 6つのマルチモーダルモデル(4つの一般目的、2つの専門)を用いて診断レポートを生成する。
- 三者の優越判定(AI superior / physician superior / equivalent)の独立審査として Claude 3.5 Sonnet を用いる。
- モデル間の好み比率を比較するために Bonferroni補正付きのカイ2乗検定を適用する。
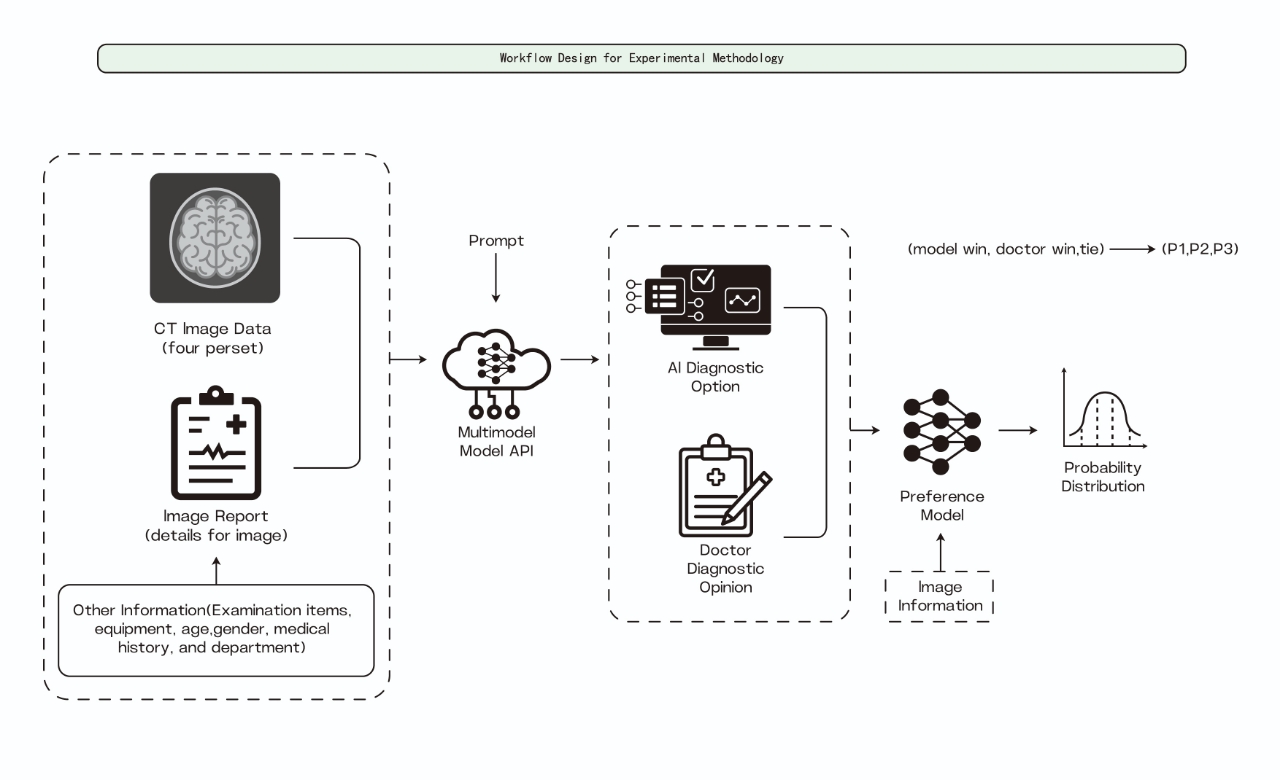
実験結果
リサーチクエスチョン
- RQ1複雑な腹部CT診断において、一般目的のマルチモーダルモデルは医師を上回ることができるか?
- RQ2多構造診断タスクにおいて、専門の視覚モデルは一般目的モデルとどう比較されるか?
- RQ3提案された好みベースの評価はAIと人間の診断能力を信頼性高く識別できるか?
主な発見
| Model | AI Superior (%) | Physician Superior (%) | Equivalent (%) | Total Cases | p-value |
|---|---|---|---|---|---|
| Llama 3.2-90B | 85.27 | 13.34 | 1.39 | 3,000 | < 0.001 |
| GPT-4 | 83.08 | 15.53 | 1.39 | 3,000 | < 0.001 |
| GPT-4o | 81.72 | 16.89 | 1.39 | 3,000 | < 0.001 |
| Gemini-1.5 | 79.35 | 13.51 | 7.14 | 3,000 | < 0.001 |
| BLIP2 | 41.36 | 53.25 | 5.39 | 3,000 | 0.047 |
| Llava | 46.77 | 48.84 | 4.39 | 3,000 | 0.052 |
- 一般目的モデルは多くのケースで医師の診断を上回り、Llama 3.2-90Bは85.27%の AI Superior を達成。
- GPT-4、GPT-4o、Gemini-1.5 も高い AI Superior率を示す(83.08%、81.72%、79.35%)。
- 専門の視覚モデル BLIP2 および Llava はより低い AI Superior率(41.36%、46.77%)を達成。
- 同等率はほとんどのモデルで低く(約1.39%)、明確な性能差を示す。
- 統計検定では一般目的モデルで p-values < 0.001 を示す;BLIP2 と Llava はそれぞれ p = 0.047 および p = 0.052。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。