[論文レビュー] Conformer: Convolution-augmented Transformer for Speech Recognition
Conformerは畳み込みと自己注意を組み合わせ、局所的およびグローバルな依存関係をモデリングしており、複数のパラメータスケールでLMあり/なしのいずれでもLibriSpeechのWERで最先端を達成します。
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
研究の動機と目的
- エンドツーエンドASRモデルに、局所的かつグローバルな音声特徴の効率的なキャプチャを促す。
- Conformerブロックを提案し、畳み込みと自己注意をMacaronスタイルのフィードフォワード層と結合する。
- LibriSpeechの複数のモデルサイズで、パラメータ効率の高い性能の利点を示す。
- 設計選択(アテンションヘッド、カーネルサイズ、FFN配置)を分析し、性能向上の要因を理解する。
提案手法
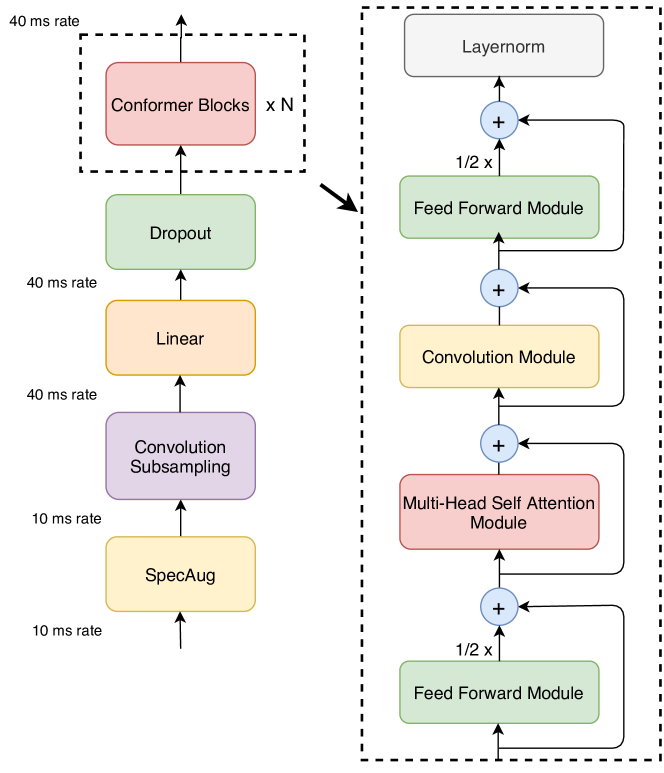
- FFN、マルチヘッド自己注意、畳み込み、二つめのFFNという4つのサブブロックを持つConformerエンコーダを導入する。
- 長さ耐性のためにMHSAで相対正弦位置エンコーディングを使用する。
- ゲーティング機構(GLU)と深層畳み込みを備えた畳み込みモジュールを実装し、バッチ正規化とSwish活性化を適用する。
- Macaron-Netにインスパイアされた半ステップFFNモジュールをMHSAとConvolutionの周りに配置し、半ステップ残差と最終層正規化を行う。
- SpecAugment、ドロップアウト、分散ノイズ、Adamオプティマイザで訓練し、デコード時の浅い結合のために3層LSTM言語モデルを使用する。
- LibriSpeechの10.3M、30.7M、118.8MパラメータでS/M/Lの3サイズを評価する。
実験結果
リサーチクエスチョン
- RQ1畳み込み拡張トランスフォーマーは、純粋なトランスフォーマーやCNNよりも局所的およびグローバルな依存関係をより効率的に捉えられるのか?
- RQ2設計上の選択(Macaron FFN、MHSAの前後の畳み込み、カーネルサイズ、ヘッド数)がASRの性能に与える影響は何か?
- RQ3Conformerは、LMの有無にかかわらず、異なるパラメータ予算でLibriSpeech上でどのように性能を発揮するか?
主な発見
| Model | # Params (M) | WER Without LM (test-clean) | WER Without LM (test-other) | WER With LM (test-clean) | WER With LM (test-other) | Notes |
|---|---|---|---|---|---|---|
| Conformer(S) | 10.3 | 2.7 | 6.3 | 2.1 | 5.0 | Dev set and test set results with 10M-parameter regime |
| Conformer(M) | 30.7 | 2.3 | 5.0 | 2.0 | 4.3 | Mid-size model outperforming prior Transformer Transducer |
| Conformer(L) | 118.8 | 2.1 | 4.3 | 1.9 | 3.9 | Large model achieving SOTA on LibriSpeech |
- Conformerはモデルサイズを問わずLibriSpeechの結果をSOTAに達成し得る。例として、largeモデルはLMなしで2.1%/4.3%、LMありで1.9%/3.9%のWERを達成。
- 10.3M (S) モデル: 2.7% test-clean / 6.3% test-other(LMなし)。2.1% / 5.0%(LMあり)。
- 30.7M (M) モデル: 2.3% test-clean / 5.0% test-other(LMなし)。2.0% / 4.3%(LMあり)。
- 118.8M (L) モデル: 2.1% test-clean / 4.3% test-other(LMなし)。1.9% / 3.9%(LMあり)。
- アブレーションにより、畳み込みサブブロックとMacaron FFNの組み合わせが重要であること、MHSAの後に畳み込みを配置する方が有益であること、カーネルサイズを32まで大きくすると性能が改善すること、ヘッド数を最大16まで増やすと開発セットでの精度が向上することが示された。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。