[論文レビュー] Consistency-guided Prompt Learning for Vision-Language Models
CoPrompt は、 prompting と adapters を入力 perturbations と組み合わせた一貫性ガイド付きファインチューニングフレームワークを導入し、vision-language モデルの few-shot 下流性能を改善しつつ zero-shot の一般化を維持します。11 datasets で base-to-novel、クロス-dataset、ドメイン一般化の最先端の結果を達成します。
We propose Consistency-guided Prompt learning (CoPrompt), a new fine-tuning method for vision-language models. Our approach improves the generalization of large foundation models when fine-tuned on downstream tasks in a few-shot setting. The basic idea of CoPrompt is to enforce a consistency constraint in the prediction of the trainable and pre-trained models to prevent overfitting on the downstream task. Additionally, we introduce the following two components into our consistency constraint to further boost the performance: enforcing consistency on two perturbed inputs and combining two dominant paradigms of tuning, prompting and adapter. Enforcing consistency on perturbed input serves to further regularize the consistency constraint, thereby improving generalization. Moreover, the integration of adapters and prompts not only enhances performance on downstream tasks but also offers increased tuning flexibility in both input and output spaces. This facilitates more effective adaptation to downstream tasks in a few-shot learning setting. Experiments show that CoPrompt outperforms existing methods on a range of evaluation suites, including base-to-novel generalization, domain generalization, and cross-dataset evaluation. On generalization, CoPrompt improves the state-of-the-art on zero-shot tasks and the overall harmonic mean over 11 datasets. Detailed ablation studies show the effectiveness of each of the components in CoPrompt. We make our code available at https://github.com/ShuvenduRoy/CoPrompt.
研究の動機と目的
- Address overfitting when fine-tuning large vision-language foundation models in few-shot settings.
- Enforce consistency between trainable and pre-trained models on both text and image branches.
- Enhance the consistency constraint with input perturbations and a combined prompting-adapter framework.
- Demonstrate improved base-to-novel generalization, cross-dataset evaluation, and domain generalization over prior SOTA methods.
提案手法
- Adopt CLIP as the vision-language backbone and extend it with multi-modal prompting.
- Introduce a cosine-based consistency loss between trainable and pre-trained embeddings for both text and image branches.
- Use input perturbations: GPT-generated descriptive text for the text branch and image augmentations for the image branch.
- Incorporate adapters on both text and image branches to increase learning capacity while applying the consistency constraint.
- Combine the consistency loss with a supervised loss into a final objective L = L_ce + lambda * L_cc.
実験結果
リサーチクエスチョン
- RQ1Can a consistency-guided fine-tuning approach maintain zero-shot capabilities while improving few-shot downstream performance?
- RQ2Does enforcing cross-modal consistency on perturbed inputs improve generalization to novel classes and across datasets?
- RQ3What is the impact of adding adapters and prompting in a unified framework under a consistency constraint?
- RQ4How do different components (text vs. image consistency, perturbations, adapters) contribute to overall performance?
主な発見
| 手法 | ベース | ノベル | 調和平均 |
|---|---|---|---|
| CLIP | 69.34 | 74.22 | 71.70 |
| CoOp | 82.69 | 63.22 | 71.66 |
| Co-CoOp | 80.47 | 71.69 | 75.83 |
| ProGrad | 82.48 | 70.75 | 76.16 |
| KgCoOp | 80.73 | 73.60 | 77.00 |
| MaPLe | 82.28 | 75.14 | 78.55 |
| CoPrompt | 84.00 | 77.23 | 80.48 |
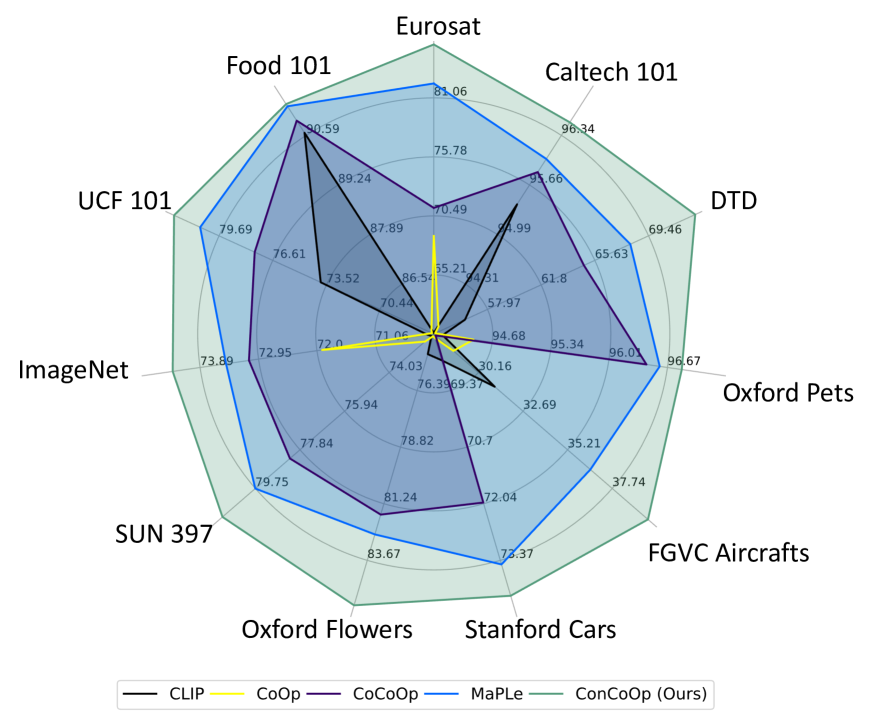
- CoPrompt achieves state-of-the-art base-to-novel generalization, with a 2.09 percentage point improvement in novel accuracy over the prior SOTA.
- CoPrompt attains a 1.93 percentage point improvement in harmonic mean over MaPLe across 11 datasets.
- On average across datasets, CoPrompt surpasses prior methods in base accuracy and maintains or improves novel accuracy, mitigating base-vs-novel trade-offs.
- CoPrompt demonstrates strong cross-dataset and domain generalization, with notable gains on datasets like EuroSAT and DTD.
- Ablation studies show adapters, input perturbations, and the consistency constraint each contribute to performance, with text-consistency having notable impact and cosine distance as the effective criterion.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。