[論文レビュー] Constrained Deep Networks: Lagrangian Optimization via Log-Barrier Extensions
本稿では、初期の実行可能解を必要とせず、暗黙の双対変数を用いて制約付き深層畳み込みニューラルネットワーク(CNN)におけるラグランジュ最適化を近似する対数バリア拡張を提案する。安定的で高精度な学習が可能になる。特に高い制約負荷下でも、ペナルティ法や明示的ラグランジュ法を上回る精度、制約満たし、学習安定性を示す。
This study investigates imposing hard inequality constraints on the outputs of convolutional neural networks (CNN) during training. Several recent works showed that the theoretical and practical advantages of Lagrangian optimization over simple penalties do not materialize in practice when dealing with modern CNNs involving millions of parameters. Therefore, constrained CNNs are typically handled with penalties. We propose *log-barrier extensions*, which approximate Lagrangian optimization of constrained-CNN problems with a sequence of unconstrained losses. Unlike standard interior-point and log-barrier methods, our formulation does not need an initial feasible solution. The proposed extension yields an upper bound on the duality gap -- generalizing the result of standard log-barriers -- and yielding sub-optimality certificates for feasible solutions. While sub-optimality is not guaranteed for non-convex problems, this result shows that log-barrier extensions are a principled way to approximate Lagrangian optimization for constrained CNNs via implicit dual variables. We report weakly supervised image segmentation experiments, with various constraints, showing that our formulation outperforms substantially the existing constrained-CNN methods, in terms of accuracy, constraint satisfaction and training stability, more so when dealing with a large number of constraints.
研究の動機と目的
- 弱教師付き学習において、深層畳み込みニューラルネットワーク(CNN)の出力に硬い不等式制約を課える課題に対処すること。
- 勾配が大きく、制約満たしが不十分となるペナルティ法の限界を克服すること。
- 深層ネットワークにおいて計算コストが高く、不安定なため、ラグランジュ最適化における明示的双対変数更新の必要性を排除すること。
- 対数バリア拡張を用いて暗黙の双対変数を介し、制約付きCNNのための原理的で制約なしの最適化フレームワークを提供すること。
- 特に多数の競合する制約を扱う場合に、安定した学習と正確な制約満たしを可能にすること。
提案手法
- 明示的双対変数更新を避けるために、制約なし損失の系列を通じてラグランジュ最適化を近似する対数バリア拡張を導入する。
- 制約違反に対して対数バリア関数を用いたペナルティを導入することで、制約付きCNN問題を定式化する。
- 双対ギャップの上界を導出し、標準的な対数バリア双対性結果を一般化し、実行可能解における部分最適性の証明を可能にする。
- 確率的勾配降下法(SGD)を用いて拡張損失を最適化することで、標準的な深層学習の学習パイプラインと互換性を持つ。
- 対数バリア定式化を損失関数に直接統合し、追加の最適化ループが不要なエンドツーエンド学習を可能にする。
- 古典的内点法とは異なり、損失関数にバリア関数を埋め込むことで、初期の実行可能解の必要性を排除する。
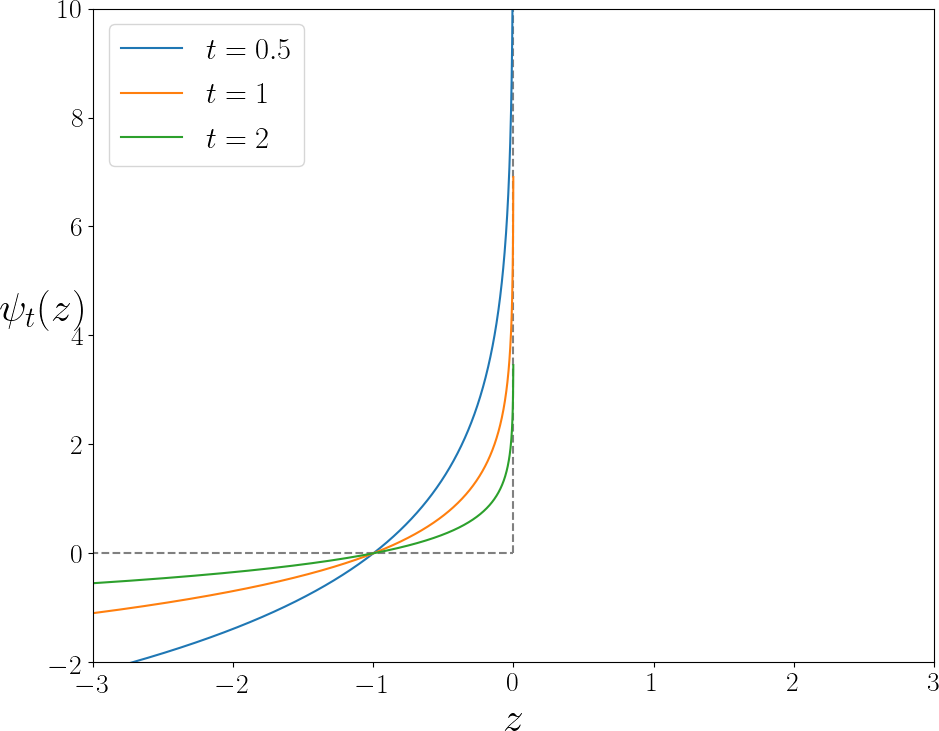
実験結果
リサーチクエスチョン
- RQ1明示的双対変数更新や初期実行可能性がなくても、対数バリア拡張が深層畳み込みニューラルネットワーク(CNN)におけるラグランジュ最適化を効果的に近似できるか。
- RQ2ペナルティ法や明示的ラグランジュ法と比較して、制約満たしと学習安定性の観点で、本手法はどのように異なるか。
- RQ3多数の競合する制約を扱う場合、本手法は性能と安定性を維持できるか。
- RQ4対数バリア拡張によって得られる双対ギャップの上界は、制約付きCNN学習における部分最適性証明として機能できるか。
- RQ5弱教師付きセグメンテーションにおいて、本手法は既存の制約付きCNNアプローチを上回る状況はどのようなものか。
主な発見
- 合成データセットでは、提案手法の平均DSCは0.945 ± 0.001を達成し、標準ラグランジュ法(0.005 ± 0.014)やReLUラグランジュ法(0.798 ± 0.006)を顕著に上回った。
- PROMISE12医療画像セグメンテーションデータセットでは、本手法のDSCは0.813 ± 0.024を達成したが、他のすべての手法(ペナルティ法やReLUラグランジュ法)は0.000 ± 0.000を記録した。
- 本手法は唯一、医療タスクで空でないセグメンテーションを生成し、高い制約複雑性下でも強靭性を示した。
- 図4に示すように、対数バリア拡張を用いた学習は、性能と制約満たしの両面で、学習エポック全体にわたり優れた安定性を示した。
- 本手法は最大で5%の計算オーバーヘッドに留まり、標準的およびReLUラグランジュ法の25%の遅延と比較して、顕著に効率的であった。
- 双対ギャップの上界は、本手法の有効性を理論的に裏付けるものであり、制約付きCNNに標準的な対数バリア双対性結果を一般化した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。