[論文レビュー] Context Matters: A Strategy to Pre-train Language Model for Science Education
本論文は、同領域の科学教育データに基づくBERTベースモデルの継続的事前学習が、学生の科学的文章の自動採点を改善することを示しており、SR2-BERTとSR2-SciBERTが下流タスクで最良の結果を達成します。
This study aims at improving the performance of scoring student responses in science education automatically. BERT-based language models have shown significant superiority over traditional NLP models in various language-related tasks. However, science writing of students, including argumentation and explanation, is domain-specific. In addition, the language used by students is different from the language in journals and Wikipedia, which are training sources of BERT and its existing variants. All these suggest that a domain-specific model pre-trained using science education data may improve model performance. However, the ideal type of data to contextualize pre-trained language model and improve the performance in automatically scoring student written responses remains unclear. Therefore, we employ different data in this study to contextualize both BERT and SciBERT models and compare their performance on automatic scoring of assessment tasks for scientific argumentation. We use three datasets to pre-train the model: 1) journal articles in science education, 2) a large dataset of students' written responses (sample size over 50,000), and 3) a small dataset of students' written responses of scientific argumentation tasks. Our experimental results show that in-domain training corpora constructed from science questions and responses improve language model performance on a wide variety of downstream tasks. Our study confirms the effectiveness of continual pre-training on domain-specific data in the education domain and demonstrates a generalizable strategy for automating science education tasks with high accuracy. We plan to release our data and SciEdBERT models for public use and community engagement.
研究の動機と目的
- 学生の科学的 writingsの自動採点を動機づけ、教師の注釈作業負担を軽減する。
- 科学教育タスクにおけるBERTベースのモデル性能が、領域特化の事前学習データで改善されるかを調査する。
- BERTとSciBERTのバリアント間でのドメイン内の文脈化戦略を比較する。
- 下流の採点タスクのための学生回答に対する継続的な事前学習の有効性を示す。
- SciEdBERTモデルをコミュニティ利用のために提供・公開するためのスケーラブルなアプローチを提供する。
提案手法
- ファインチューニング前に、同領域データで事前学習済みモデルを文脈化するピラミッド型トレーニング手法を採用する。
- SciEdJ(科学教育ジャーナル)、SR1(50,000件以上の学生回答)、SR2(科学的主張回答)の3つのデータ源でモデルを事前学習させる。
- SR1からの7つのタスクを用いた下流タスクへのファインチューニング(7T)、SR2タスクを用いた下流タスクへのファインチューニング(4T)を行う。
- 基礎となるBERTとSR1-BERT、およびSciBERT、SciEdJ-BERT、SciEdJ-SciBERT、SR2-BERT、SR2-SciBERTを含む追加バリアントを比較し、文脈化効果を評価する。
- 複数の記述応答タスクに対するタスクレベルの正解率で性能を評価する。
- 事前学習データと下流タスクの整合性を最大化するため、継続的な事前学習レジームを採用する。
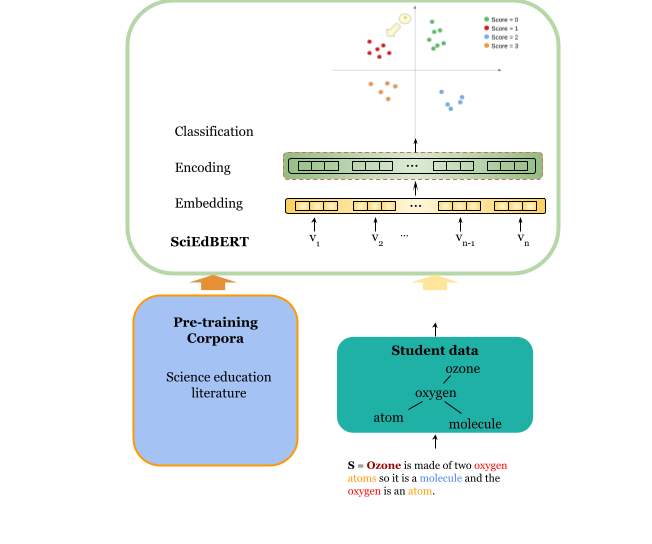
実験結果
リサーチクエスチョン
- RQ1ドメイン内の継続的な事前学習は、一般的なBERTベースラインと比べて自動採点の正確性を改善するか。
- RQ2SciEdJ、SR1、SR2を用いた文脈化は、科学教育の採点タスクにおけるモデル性能にどう影響するか。
- RQ3構成回答における下流の正解率が最も高いモデルのバリアントはどれか(BERT対SciBERT、異なる領域データを用いる場合)。
- RQ4特定の採点タスクにファインチューニングする前に、タスク関連の文脈で訓練することに利点はあるか。
主な発見
| Table 1 - 7T task accuracies by model | Table 2 - 4T task accuracies by model | ||||
|---|---|---|---|---|---|
| H4-2 | 0.913 | 0.929 | |||
| H4-3 | 0.831 | 0.831 | |||
| H5-2 | 0.958 | 0.970 | |||
| J2-2 | 0.920 | 0.926 | |||
| J6-2 | 0.959 | 0.973 | |||
| J6-3 | 0.845 | 0.845 | |||
| R1-2 | 0.864 | 0.864 | |||
| Average | 0.904 | 0.912 | |||
| Table 2 G4 | 0.792 | 0.804 | 0.815 | 0.821 | 0.815 |
| G6 | 0.766 | 0.727 | 0.742 | 0.719 | 0.766 |
| S2 | 0.895 | 0.882 | 0.889 | 0.915 | 0.928 |
| S3 | 0.934 | 0.954 | 0.921 | 0.954 | 0.954 |
- SR1-BERTは平均で基準のBERTをやや上回る(0.912対0.904)。
- SR2-SciBERTは4Tタスクで最高の平均精度を達成(0.866)。
- SR2-BERTも高いパフォーマンスを示し(平均0.852)、個別タスクでSciEdJ系のバリアントと同等かそれ以上になることが多い。
- 下流タスク言語(SR2)でモデルを文脈化すると、広範なドメイン言語のみよりタスクごとの性能が向上する。
- SciEdJ-SciBERTと SciEdJ-BERTは、評価されたモデルの中で平均的に最悪のパフォーマンスを示し、科学教育系の論文だけでは学生の文章言語を混乱させる可能性があることを示唆している。
- 全体として、特に下流タスクと整合したドメイン特異データでの継続的事前学習は、学生の科学的文章の自動採点を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。