[論文レビュー] Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA
C-LoRAを導入。継続学習を伴う自己正則化型低秩適応を Stable Diffusion の cross-attention に適用し、過去の概念を忘れずに逐次的に細粒度概念を学習する。ランダムトークンによるカスタマイズ戦略を追加。継続的なテキストから画像へのカスタマイズで最先端の性能を示し、継続的な画像分類への転移も達成。
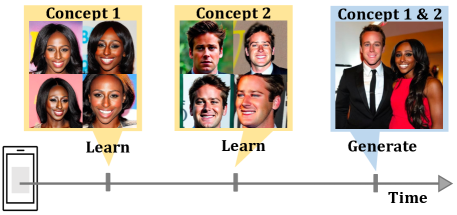
Recent works demonstrate a remarkable ability to customize text-to-image diffusion models while only providing a few example images. What happens if you try to customize such models using multiple, fine-grained concepts in a sequential (i.e., continual) manner? In our work, we show that recent state-of-the-art customization of text-to-image models suffer from catastrophic forgetting when new concepts arrive sequentially. Specifically, when adding a new concept, the ability to generate high quality images of past, similar concepts degrade. To circumvent this forgetting, we propose a new method, C-LoRA, composed of a continually self-regularized low-rank adaptation in cross attention layers of the popular Stable Diffusion model. Furthermore, we use customization prompts which do not include the word of the customized object (i.e., "person" for a human face dataset) and are initialized as completely random embeddings. Importantly, our method induces only marginal additional parameter costs and requires no storage of user data for replay. We show that C-LoRA not only outperforms several baselines for our proposed setting of text-to-image continual customization, which we refer to as Continual Diffusion, but that we achieve a new state-of-the-art in the well-established rehearsal-free continual learning setting for image classification. The high achieving performance of C-LoRA in two separate domains positions it as a compelling solution for a wide range of applications, and we believe it has significant potential for practical impact. Project page: https://jamessealesmith.github.io/continual-diffusion/
研究の動機と目的
- 継続拡散の問題定義:過去の概念への再訓練を伴わず、テキスト-to-image 拡散の逐次的で細粒度な概念カスタマイズ。
- C-LoRA の提案:cross-attention における継続的、自己正則化型低秩アダプタと、ランダムで非名寄せベースのパーソナライズトークン。
- C-LoRA が災害的忘却を抑制し、継続拡散ベンチマークでベースラインを上回ることを示す。
- C-LoRA がImageNet-Rなどの画像分類のリハーサル不要の継続学習で最先端の結果を達成することを示す。
提案手法
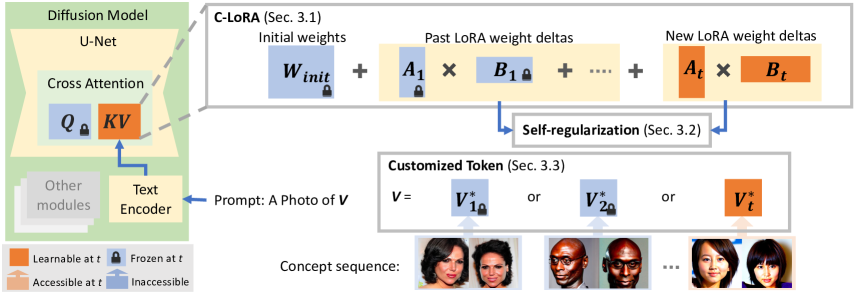
- Stable Diffusion の cross-attention のキー/value (K,V) 投影のみを LoRA スタイルの低秩アダプタで変更する。
- 過去に適合した重みの変化を過去の LoRA デルタの和(Hadamard 正則化)でペナルティする継続的自己正則化損失を導入。
- 各タスクごとに LoRA パラメータを用い、元の重みと融合して W^{K,V}_{t}=W^{K,V}_{init} + sum_{t'<t} A_{t'}^{K,V} B_{t'}^{K,V} + A_{t}^{K,V} B_{t}^{K,V}。
- カスタマイズされたトークン戦略を採用:N 個のパーソナライズトークンをランダムに初期化して追加し、プロンプトから概念語を除去して干渉を低減。
- 正則化強度の単純な指数スイープで訓練し、LoRA パラメータのみ更新してパラメータコストを低く保つ(再生データの保存なし)。
- 複数概念生成能力を示し、Textual Inversion、DreamBooth、Custom Diffusion、リハーサル不要の継続学習ベースラインと比較。
実験結果
リサーチクエスチョン
- RQ1概念が逐次到着する場合、致命的な忘却を伴わずに継続的で細粒度なテキスト-to-画像概念カスタマイズを実現できるか?
- RQ2cross-attention における自己正則化型低秩適応(C-LoRA)は、継続拡散における既存の拡張カスタマイズ手法を上回るか?
- RQ3パーソナライズトークンのランダム初期化と概念語の除去は継続学習の性能を向上させ、マルチ概念生成を可能にするか?
- RQ4C-LoRA の利得は、ImageNet-R のような画像分類ベンチマークのリハーサル不要の継続学習にも及ぶか?
- RQ5既存のアプローチ(Custom Diffusion、LoRA、再生ベース手法)と比較して、C-LoRA のパラメータ・プライバシー上の影響はどのようか?
主な発見
- C-LoRA は忘却を著しく低減し、Celeb-A HQ および Google Landmarks データセットで逐次学習した概念の最終生成品質を向上させる。
- Textual Inversion、DreamBooth、Custom Diffusion(逐次/マージ)と比較して、C-LoRA は忘却を低い MMD、概念間の整合性を高く、訓練可能なパラメータをはるかに少なく実現。
- ランダムで非名寄せベースのパーソナライズトークン戦略と対象語の除去は概念間の干渉を減らし、マルチ概念生成を改善。
- この手法は ImageNet-R でのリハーサル不要の継続学習において最先端の性能を達成し、LwF、L2P、DualPrompt、CODA-Prompt、摂動変種を上回る。
- C-LoRA は追加パラメータコストがごくわずかで、再生データなしの自己正則化機構を備え、顔領域とランドマーク領域の両方で少なくとも10個の逐次概念にスケール可能。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。