[論文レビュー] Continual Pre-training of Language Models
DASを提案する。継続的なドメイン適応前学習のためのソフトマスキングベースの手法で、ラベルなしドメインコーパスの連続列から学習しつつ、忘却を緩和し知識移転を可能にする。
Language models (LMs) have been instrumental for the rapid advance of natural language processing. This paper studies continual pre-training of LMs, in particular, continual domain-adaptive pre-training (or continual DAP-training). Existing research has shown that further pre-training an LM using a domain corpus to adapt the LM to the domain can improve the end-task performance in the domain. This paper proposes a novel method to continually DAP-train an LM with a sequence of unlabeled domain corpora to adapt the LM to these domains to improve their end-task performances. The key novelty of our method is a soft-masking mechanism that directly controls the update to the LM. A novel proxy is also proposed to preserve the general knowledge in the original LM. Additionally, it contrasts the representations of the previously learned domain knowledge (including the general knowledge in the pre-trained LM) and the knowledge from the current full network to achieve knowledge integration. The method not only overcomes catastrophic forgetting, but also achieves knowledge transfer to improve end-task performances. Empirical evaluation demonstrates the effectiveness of the proposed method.
研究の動機と目的
- ラベルなしドメインコーパスの連続列にさらされる言語モデルの継続的なドメイン適応前学習(continual DAP-training)を研究する。
- 領域間の知識移転を可能にしつつ、壊滅的忘却を防ぐ手法を開発する。
- 事前学習データへアクセスせずに、ユニット重要度の代理測度を用いて一般的LM知識を保持する。
- 対照的信号を通じて新しいドメイン知識と既に学習した知識の統合を促進する。
- 複数のラベルなしドメインコーパスとエンドタスク分類でアプローチを評価する。
提案手法
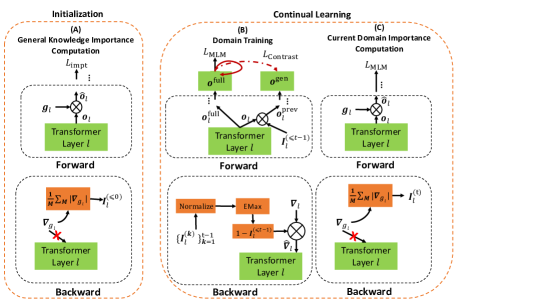
- 継続的な DAP-training の間に後向き勾配を制約するため、単位ごとの重要度を用いたソフトマスキング機構を導入する。
- 事前学習データへアクセスせずに一般的 LM 知識のユニット重要度を推定するため、代理KL-divergenceに基づく頑健性損失を定義する。
- 要素ごとの最大値を用いてドメイン間でユニット重要度を蓄積し、 backward パスでソフトマスクを適用して新しいドメインを学習しつつ過去の知識を保持する。
- 蓄積済み(過去)知識と完全な(過去+現在)知識間の補完的表現を促す対照学習損失を用いて知識統合を促進する。
- 各ドメインの学習後に現在ドメインのユニット重要度を計算し、次のドメインに備えて蓄積された重要度を更新する。
- エンドタスクファインチューニングにはドメインIDは不要で、LMは統合されたすべての知識を保持する。
実験結果
リサーチクエスチョン
- RQ1継続的なドメイン適応前学習を全てのLM更新で実現することは、パラメータの isolated ではなく可能か。
- RQ2継続的 DAP-training においてドメイン間の知識移転を可能にしつつ壊滅的忘却を防ぐにはどうするか。
- RQ3ユニット重要度に導かれたソフトマスキング機構は一般的LM知識を保護しクロスドメイン転送を支援できるか。
- RQ4過去のドメインと現在のドメイン間の統合を促進する対照学習目標は知識統合を改善するか。
- RQ5プリ学習データにアクセスせずに代理ベースのユニット重要度測定は一般知識の保持の初期化に有効か。
主な発見
- DASは複数ドメインにわたるエンドタスク分類で広範なベースラインを上回る。
- DASは強力な知識移転と否定的忘却率を達成しており、忘却防止とクロスドメイン転送を効果的に示す。
- この継続設定での直接的な全LMドメイン学習(DAS のような)は、アダプターやプロンプトベースのドメイン適応ベースラインを上回る。
- 過去の知識と現在の知識を対比させる対照的目的は、過去のみの対比より知識統合を促進する。
- 代理KL-divergenceに基づく測度は元の事前学習データへアクセスせずに一般知識のユニット重要度を効果的に推定できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。