[論文レビュー] Continuum Attention for Neural Operators
本論文は注意機構を無限次元の関数空間間の写像として定式化し、それが有限次元の実装で近似可能であることを証明し、パッチベースで離散化不変なアーキテクチャを持つ普遍近似性を備えたトランスフォーマー型ニューラル演算子を開発する。
Transformers, and the attention mechanism in particular, have become ubiquitous in machine learning. Their success in modeling nonlocal, long-range correlations has led to their widespread adoption in natural language processing, computer vision, and time series problems. Neural operators, which map spaces of functions into spaces of functions, are necessarily both nonlinear and nonlocal if they are universal; it is thus natural to ask whether the attention mechanism can be used in the design of neural operators. Motivated by this, we study transformers in the function space setting. We formulate attention as a map between infinite dimensional function spaces and prove that the attention mechanism as implemented in practice is a Monte Carlo or finite difference approximation of this operator. The function space formulation allows for the design of transformer neural operators, a class of architectures designed to learn mappings between function spaces. In this paper, we state and prove the first universal approximation result for transformer neural operators, using only a slight modification of the architecture implemented in practice. The prohibitive cost of applying the attention operator to functions defined on multi-dimensional domains leads to the need for more efficient attention-based architectures. For this reason we also introduce a function space generalization of the patching strategy from computer vision, and introduce a class of associated neural operators. Numerical results, on an array of operator learning problems, demonstrate the promise of our approaches to function space formulations of attention and their use in neural operators.
研究の動機と目的
- Neural operators のための関数空間設定における注意の動機づけと形式化。
- 実用的な注意が連続演算子のモンテカルロ/差分近似であることを示す。
- 関数空間間の写像を学習できるように、離散化不変であるトランスフォーマー型ニューラル演算子を定義する。
- トランスフォーマー型ニューラル演算子の初の普遍近似結果を確立する。
- 多次元ドメイン上での効率的かつスケーラブルな演算子学習を可能にするパッチベースの注意を導入する。
提案手法
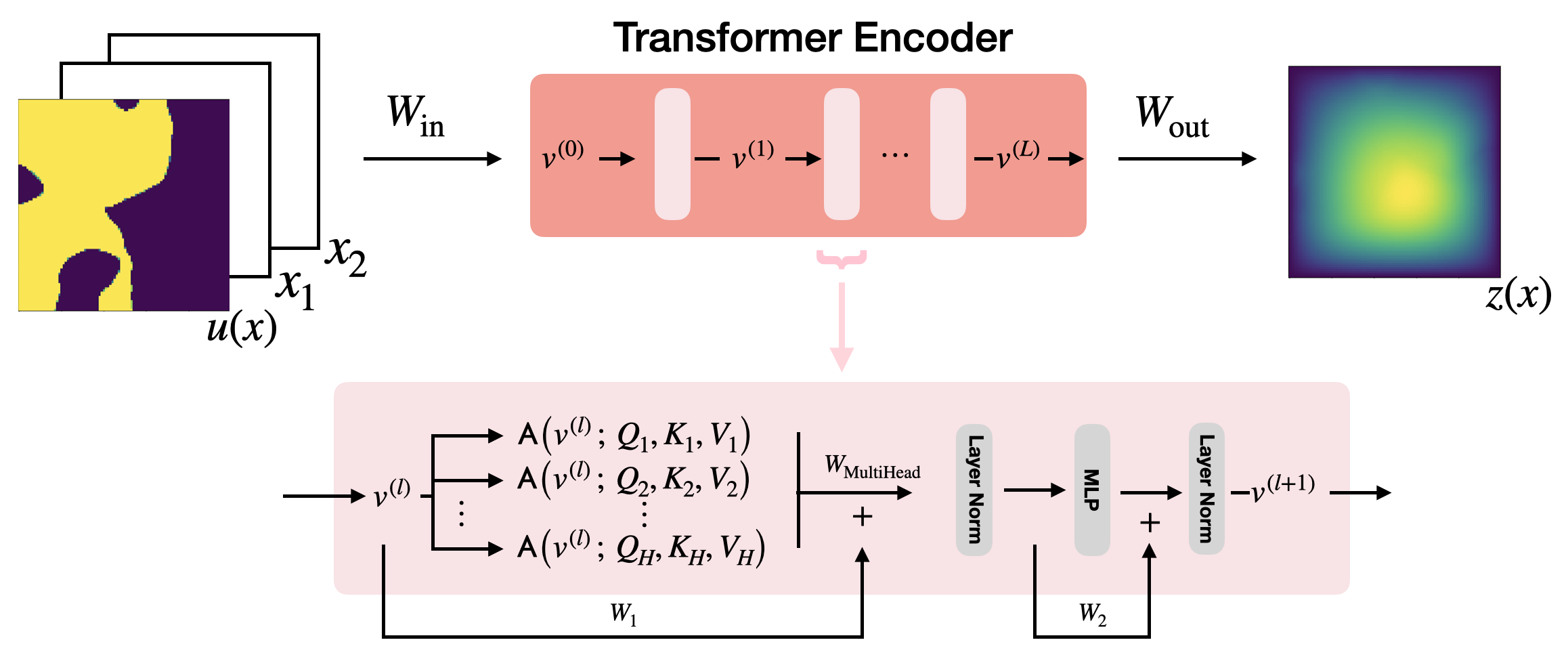
- 自己注意およびクロス注意を、ドメインD上の関数のBanach空間上で作用する演算子として定式化する。
- 実用的な注意が連続注意演算子のモンテカルロ近似であることを証明する(定理6および12)。
- 連続注意写像とそれらのパッチ化された変種を定義し、離散化不変の学習を可能にする。
- 関数空間間を写像するトランスフォーマー型ニューラル演算子を構築し、普遍近似定理を証明する。
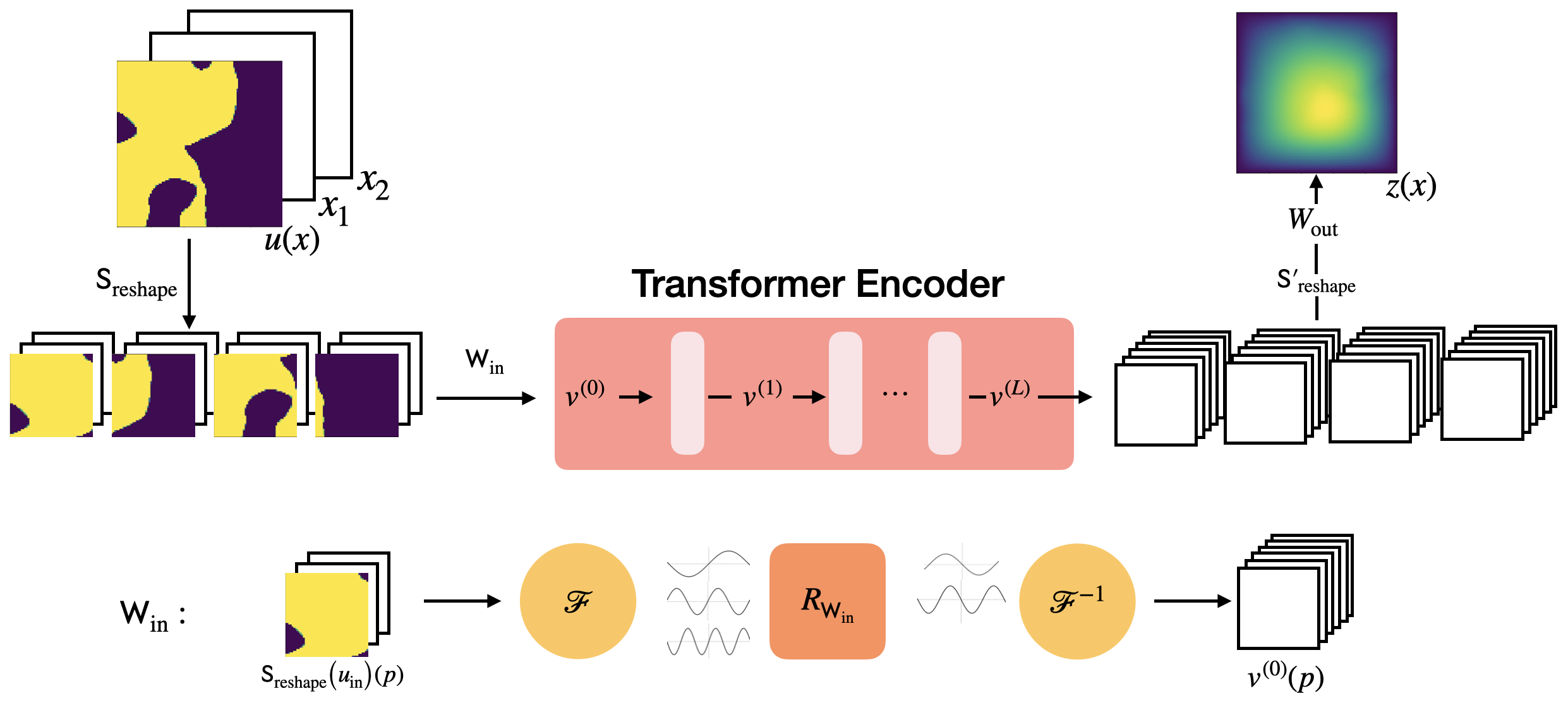
- ドメインをパッチに partition し、パッチ間で注意を適用することでパッチ注意を導入する(パッチングフレームワーク)。
- 演算子学習問題に関する数値実験を提供し、有効性を示す。
実験結果
リサーチクエスチョン
- RQ1無限次元の関数空間で注意機構を厳密に定義するにはどうすればよいか。
- RQ2離散化された注意機構は連続対応物を誤差制御つきで近似できるか。
- RQ3トランスフォーマー型ニューラル演算子は関数空間間の写像に対して普遍近似性を持つか。
- RQ4パッチベースの注意戦略は、PDEおよび関連問題に適用可能な離散化不変・スケーラブルなニューラル演算子を生み出すか。
主な発見
- 注意は関数空間間の写像として定式化され、実践で使用される有限次元実装で近似可能であることを示す。
- 連続自己注意と有限離散化との誤差を定量化する近似定理を示し、クロス注意についても同様の結果が成り立つ。
- 離散化/不変性を持ち、非格子メッシュへのゼロショット一般化をサポートするトランスフォーマー型ニューラル演算子フレームワークを確立する。
- トランスフォーマー型ニューラル演算子の初の普遍近似定理を提示する。
- パッチ注意を開発し、関数パッチを介して効率的な計算とメッシュ不変の演算子学習を実現する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。