[論文レビュー] Contrast, Attend and Diffuse to Decode High-Resolution Images from Brain Activities
本論文は、二段階のfMRI表現学習フレームワーク(DC-MAEによる事前学習とクロスモダリティ調整)を用いて、脳活動から高解像度画像を再構成するために潜在拡散モデルを条件付け、従来法より著しい改善を達成します。
Decoding visual stimuli from neural responses recorded by functional Magnetic Resonance Imaging (fMRI) presents an intriguing intersection between cognitive neuroscience and machine learning, promising advancements in understanding human visual perception and building non-invasive brain-machine interfaces. However, the task is challenging due to the noisy nature of fMRI signals and the intricate pattern of brain visual representations. To mitigate these challenges, we introduce a two-phase fMRI representation learning framework. The first phase pre-trains an fMRI feature learner with a proposed Double-contrastive Mask Auto-encoder to learn denoised representations. The second phase tunes the feature learner to attend to neural activation patterns most informative for visual reconstruction with guidance from an image auto-encoder. The optimized fMRI feature learner then conditions a latent diffusion model to reconstruct image stimuli from brain activities. Experimental results demonstrate our model's superiority in generating high-resolution and semantically accurate images, substantially exceeding previous state-of-the-art methods by 39.34% in the 50-way-top-1 semantic classification accuracy. Our research invites further exploration of the decoding task's potential and contributes to the development of non-invasive brain-machine interfaces.
研究の動機と目的
- ノイズを除去し、脳fMRI表現を再度ノイズ除去してデコード品質を改善する。
- クロスモダリティガイダンスを活用して視覚に関連する脳信号に注意を向ける。
- fMRIから高解像度で意味的に忠実な画像を生成するために潜在拡散モデルを統合する。
- ベースラインと比較してGODおよびBOLD5000データセットで卓越した再構成性能を示す。
提案手法
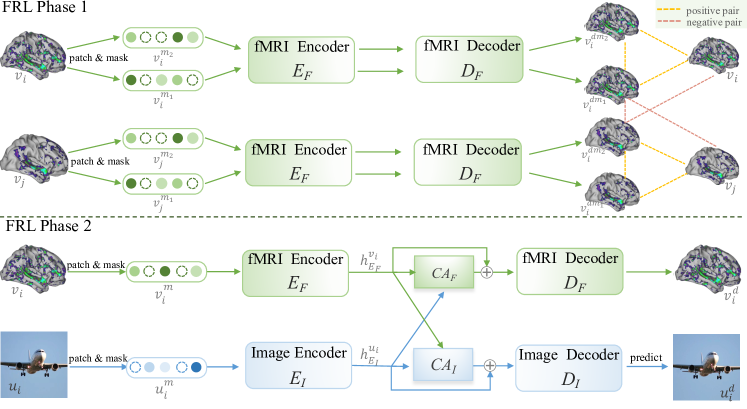
- ラベルなしfMRIデータ上でDouble-contrastive Masked Auto-Encoder (DC-MAE)を用いてfMRI特徴学習機を事前学習し、デノイズ化された表現を学習する。
- Phase 2では、クロスアテンションを用いる画像自己符号化器でfMRIエンコーダを調整し、再構成のための有益な脳パターンへの注意を導く。
- 最適化されたfMRIエンコーダを用いて潜在拡散モデル(LDM)を脳活動から画像生成へ条件付けする。
- fMRI特徴を用いたクロスアテンション条件付けでLDMを微調整し、条件付き画像生成を実行する。
- 事前学習済みImageNet分類器を用いた50-way-top-1意味的正確性に基づく評価指標を用いて意味的正確性を評価する。
実験結果
リサーチクエスチョン
- RQ1DC-MAEは個人間でfMRI表現を効果的にデノイズし整合させることができるか。
- RQ2fMRIと画像自己符号化器間のクロスモダリティガイダンスはfMRIからの視覚再構成を改善するか。
- RQ3fMRIで条件付けられた潜在拡散モデルは高解像度で意味的に正確な画像を生成できるか。
- RQ4FRL Phase 2における再構成損失とマスク比の相対的寄与はデコード性能にどのような影響を与えるか。
- RQ5提案フレームワークはGODとBOLD5000のようなデータセット間でスケーラブルか。
主な発見
- 提案モデルはGODとBOLD5000データで50-way-top-1精度が従来の最先端手法を39.34%上回る。
- 二段階のFRL(DC-MAE事前学習とクロスモダリティ調整)は高解像度かつ意味的に正確な再構成をもたらす。
- アブレーション研究は、fMRIと画像再構成の損失の結合、慎重に選択されたマスク比、およびデコーダの深さが性能に重要であることを示す。
- 本手法はGODの被験者CSI1で50-way-top-1精度が25となり、テストセットのfMRIデータをチューニングに使用していない場合でもDC-LDMと比較してGODの被験者1,2,4,5で優れた性能を示す。
- このアプローチはバイアスとディテール再構成のトレードオフを特定しており、LDM訓練におけるデータセット由来のバイアスを認識する。
![Figure 2: [a] Demo of the forward and backward processes of the diffusion model. [b] The forward process of the diffusion model which progressively corrupts an image with Gaussian noise. [c] In the backward process, the diffusion model, conditioned on our pretrained fMRI encoder, gradually denoises](https://ar5iv.labs.arxiv.org/html/2305.17214/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。