[論文レビュー] Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining
ReCon は、エンコーダ-デコーダの ReCon ブロックを介して再構成に導かれた局所的知識をグローバルな対照モデルへ転送し、対照学習と生成的な3D自己教師あり学習を統合することで、ScanObjectNN と ModelNet40 で最先端の結果を達成します。
Mainstream 3D representation learning approaches are built upon contrastive or generative modeling pretext tasks, where great improvements in performance on various downstream tasks have been achieved. However, we find these two paradigms have different characteristics: (i) contrastive models are data-hungry that suffer from a representation over-fitting issue; (ii) generative models have a data filling issue that shows inferior data scaling capacity compared to contrastive models. This motivates us to learn 3D representations by sharing the merits of both paradigms, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose Contrast with Reconstruct (ReCon) that unifies these two paradigms. ReCon is trained to learn from both generative modeling teachers and single/cross-modal contrastive teachers through ensemble distillation, where the generative student guides the contrastive student. An encoder-decoder style ReCon-block is proposed that transfers knowledge through cross attention with stop-gradient, which avoids pretraining over-fitting and pattern difference issues. ReCon achieves a new state-of-the-art in 3D representation learning, e.g., 91.26% accuracy on ScanObjectNN. Codes have been released at https://github.com/qizekun/ReCon.
研究の動機と目的
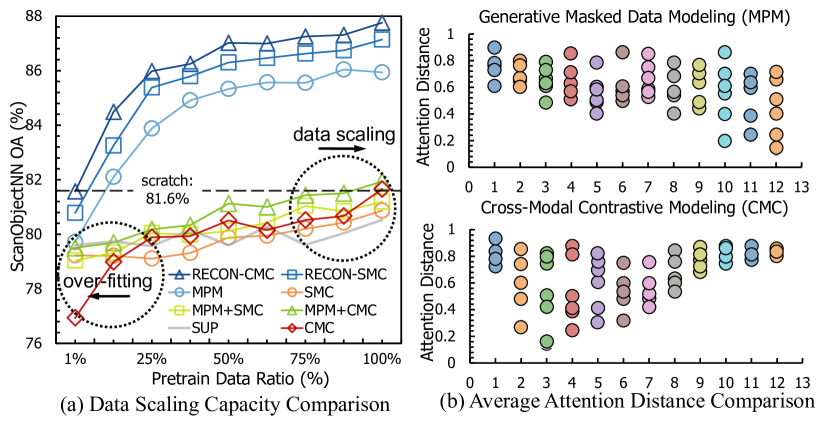
- データ集約志向とデータ充填の制限を克服するため、3D 表現における対照学習と生成的自己教師付き学習の組み合わせを動機づける。
- エンサンブル蒸留と再構成に導かれた対照フレームワークを通じて、ReCon を提案し、二つのパラダイムを統合する。
- エンコーダ-デコーダ ReCon ブロックに停止勾配を伴うクロスアテンションを導入し、単純なマルチタスク学習におけるパターン差と過適合を解決する。
- ReCon が単一モーダルおよびクロスモーダル(3D+2D+テキスト)の事前学習全般で一般化能力とデータ効率を向上させることを示す。
- 3D ベンチマークでの最先端結果を示す広範なアブレーションと転移評価を提供する。)
提案手法
- 対照学習と生成学習を複数の教師からの蒸留として位置づける。
- 再構成に導かれた埋め込みをグローバルな対照デコーダへ転送するよう、クロスアテンションを用いたエンコーダ-デコーダ Transformer アーキテクチャの ReCon ブロックを導入し、タスク衝突を避けるため停止勾配を使用。
- ShapeNet で単一モーダルとクロスモーダル入力(3D点群、レンダリングされたRGB画像、言語説明)を用いて事前学習。
- 局所的再構成指針としてマスク付き生成モデリングを用い、デコーダにはグローバルなクロスモーダル対照目標を適用。
- 対照目標には Smooth L1 距離を、再構成には Chamfer 距離を用い、クロスアテンション接続にはストップ勾配を適用。
- ScanObjectNN と ModelNet40 に対して、フル、線形/MLP、少数ショット転送プロトコルを含む評価を行い、ゼロショット転送も含む。
実験結果
リサーチクエスチョン
- RQ1アンサンブル蒸留を通じて知識を整合させることで、3D において対照学習と生成学習の共通の利点を実現できるか。
- RQ2ReCon-block を介した再構成に導かれた対照学習は、単純なマルチタスク事前学習よりも一般化能力とデータ効率を向上させるか。
- RQ3アーキテクチャと訓練の選択肢(マスキング割合、デコーダ深さ、2D 教師)は、3D タスクの ReCon 事前学習を最適化するか。
主な発見
- ReCon は新たな最先端の自己教師付き3D学習を達成し、たとえば ScanObjectNN と ModelNet40 で顕著な改善を示す。
- ReCon は単一モーダルおよびクロスモーダル設定全般で堅牢な転移性能を提供し、Point-MAE や他のSSL 手法を上回る。
- アブレーションにより、最適なマスキング、デコーダ深さ、2D ビジョン教師(ViT)が事前学習で CLIP および他の教師を上回ることが示される。
- クロスアテンションでの勾配停止は重要で、これを除去すると性能が大幅に低下する。
- ModelNet40/ModelNet10 のゼロショット結果は、PointCLIP や CLIP2Point を含むいくつかの従来法を上回る。
- ReCon はアテンションの可視化を通じて、局所的な幾何学的焦点とグローバルな3D理解の両方を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。