[論文レビュー] Contrastive Multiview Coding
本論文は Contrastive Multiview Coding (CMC) を紹介する。自己 supervised 手法として、複数の画像チャネルまたはビュー間で mutual information を最大化することによりビュー不変の表現を学習し、画像および動画のベンチマークで最先端の結果を示す。より多くのビューは表現品質を向上させ、contrastive 学習は cross-view prediction を上回る。
Humans view the world through many sensory channels, e.g., the long-wavelength light channel, viewed by the left eye, or the high-frequency vibrations channel, heard by the right ear. Each view is noisy and incomplete, but important factors, such as physics, geometry, and semantics, tend to be shared between all views (e.g., a "dog" can be seen, heard, and felt). We investigate the classic hypothesis that a powerful representation is one that models view-invariant factors. We study this hypothesis under the framework of multiview contrastive learning, where we learn a representation that aims to maximize mutual information between different views of the same scene but is otherwise compact. Our approach scales to any number of views, and is view-agnostic. We analyze key properties of the approach that make it work, finding that the contrastive loss outperforms a popular alternative based on cross-view prediction, and that the more views we learn from, the better the resulting representation captures underlying scene semantics. Our approach achieves state-of-the-art results on image and video unsupervised learning benchmarks. Code is released at: http://github.com/HobbitLong/CMC/.
研究の動機と目的
- 複数の感覚ビュー間で共有され、意味的に意味のある情報を捉えるコンパクトな表現を学習する動機づけ。
- ビュー間で相互情報を最大化するスケーラブルな multiview contrastive 学習フレームワークを開発する。
- ビュー数を増やすことが表現品質にどう影響するかを調査する。
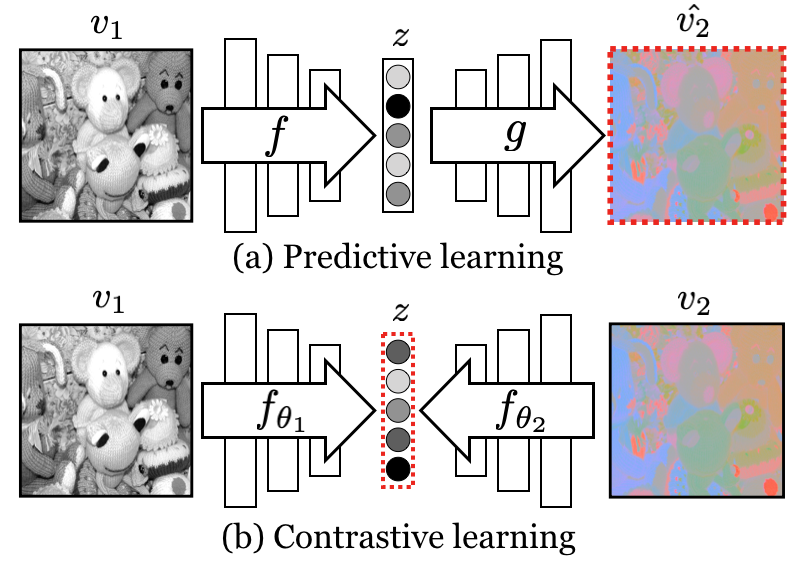
- contrastive multiview 学習を cross-view prediction および predictive learning と比較する。
- 学習した表現の downstream の認識およびセマンティックセグメンテーションタスクへの転移可能性を評価する。
提案手法
- M 個のビュー V1,...,VM と各ビュー用のエンコーダ fi を定義して潜在表現 z_i = fi(v_i) を生成する。
- cosine 類似度に基づく z-ベクトルのスコア h_theta を用いて、正例対(同じシーンの整合したビュー)を負例対(異なるシーン)と識別する対比目的を用いる。
- Two-view loss L_contrast^{V1,V2} は両方向で適用され、L(V1,V2) を形成するように加算される。
- 複数ビューのコアビューおよびフルグラフの定式化へ拡張する:コアビューは j>1 の L(V1,Vj) を合計し、フルグラフは all i<j の L(Vi,Vj) を合計する。
- Negative sampling と memory bank:管理可能な負例数で full softmax を近似し、効率的な対比のため潜在特徴を memory bank に格納する。
- 最適な critic を密度比と mutual information に関連付け、下限 I(z1;z2) ≥ log(k) − L_contrast、ここで k は負例の数。
- contrastive 学習はビュー間の共有情報を predictive(再構成)学習よりも良く捉える empirical な比較を示す。
- 画像には Lab L vs ab チャンネル、Y vs DbDr などの組み合わせ、動画には RGB フレームと光学フローを適用し、NYU-Depth-V2 にはより多くのビュー(L, ab, depth, surface normals)へ拡張する。
- 二つのエンコーダアーキテクチャと共有対比目的、オプションの memory bank、データ拡張を利用し、転移は線形プローブとセグメンテーション風タスクで評価する。
![Figure 1 : Given a set of sensory views, a deep representation is learnt by bringing views of the same scene together in embedding space, while pushing views of different scenes apart. Here we show and example of a 4-view dataset (NYU RGBD [ 53 ] ) and its learned representation. The encodings for e](https://ar5iv.labs.arxiv.org/html/1906.05849/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1複数の画像チャネルにわたってビュー不変で意味的に意味のある表現を学習できるか。
- RQ2ビュー数を増やすことは下流タスクの学習表現の品質を改善するか。
- RQ3contrastive 目的は multiview 表現学習において cross-view prediction や predictive learning より優れているか。
- RQ4core-view と full-graph の multiview 定式化は効率と情報捕捉の間でどのようにトレードオフするか。
- RQ5CMC 表現は画像分類、動画認識、セグメンテーションタスクへどの程度転移するか。
主な発見
- CMC は画像と動画のベンチマークで強力な自己監督性能を達成し、いくつかの設定で最先端に近づく。
- ビュー数が増えると表現品質が向上する(例:NYU-Depth-V2 の実験を跨いで)。
- contrastive 目的は複数ビューの組み合わせやデータセットで cross-view prediction および predictive learning を上回る。
- Full-graph multiview 定式化はすべてのビューで堅牢な表現を提供し、いくつかのタスクで監督付き性能に近づく。
- ImageNet では luminance と chrominance (L,ab) や他のカラー空間分割を用いた二ビュー CMC が top-1/top-5 精度で競合力を示し、モデル幅を拡大し追加ビューを用いると結果がさらに改善される。
- 動画タスクでは RGB フレームと光学フローを用いた CMC がいくつかのベースラインを上回り、アクション認識データセットへの転移を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。