[論文レビュー] Controllable Text-to-Image Generation with GPT-4
この研究は Control-GPT を紹介します。GPT-4 を用いて TikZ スケッチを生成し、それが ControlNet ベースの拡散モデルを導く。テキストから画像生成における空間制御で最先端を達成します。
Current text-to-image generation models often struggle to follow textual instructions, especially the ones requiring spatial reasoning. On the other hand, Large Language Models (LLMs), such as GPT-4, have shown remarkable precision in generating code snippets for sketching out text inputs graphically, e.g., via TikZ. In this work, we introduce Control-GPT to guide the diffusion-based text-to-image pipelines with programmatic sketches generated by GPT-4, enhancing their abilities for instruction following. Control-GPT works by querying GPT-4 to write TikZ code, and the generated sketches are used as references alongside the text instructions for diffusion models (e.g., ControlNet) to generate photo-realistic images. One major challenge to training our pipeline is the lack of a dataset containing aligned text, images, and sketches. We address the issue by converting instance masks in existing datasets into polygons to mimic the sketches used at test time. As a result, Control-GPT greatly boosts the controllability of image generation. It establishes a new state-of-art on the spatial arrangement and object positioning generation and enhances users' control of object positions, sizes, etc., nearly doubling the accuracy of prior models. Our work, as a first attempt, shows the potential for employing LLMs to enhance the performance in computer vision tasks.
研究の動機と目的
- 空間的制御を備えた、指示に厳密に従うテキストから画像への生成を動機づけ、可能にする。
- GPT-4 を活用して拡散モデルを導くプログラム的スケッチを作成する。
- GPT が生成したスケッチと拡散モデルの理解のギャップを、ポリゴンベースの訓練データセットを構築することで緩和する。
提案手法
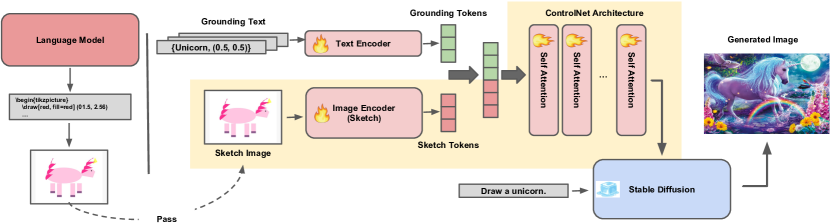
- テキストプロンプトから TikZ スケッチとオブジェクト・ grounding トークンを生成するよう GPT-4 にプロンプトを出す。
- LVIS/COCO からのインスタンスマスクをポリゴンスケッチに変換し、グラウンディング トークンとともに ControlNet をファインチューニングする。
- バックボーン拡散部を凍結したまま、ポリゴンスケッチとグラウンディング トークンを用いた COCO/LVIS 派生データセットで ControlNet をファインチューニングする。
- スケッチを物体名と位置に明示的に結びつけるために、オブジェクト・グラウンディング トークンを導入する。
- 推論時に GPT-4 を照会して、新しいプロンプトのゼロショットスケッチと対応するグラウンディング トークンを生成する。

実験結果
リサーチクエスチョン
- RQ1GPT-4 はテキストプロンプトに従う正確なプログラム的スケッチ(TikZ)を生成し、細かな画像制御を可能にできるか?
- RQ2LLM が生成したスケッチを統合することは、拡散ベースのモデルにおける空間精度とオブジェクトのグラウンディングをどの程度改善するか?
- RQ3ガイダンスとして GPT-4 のスケッチを使用する際、グラウンディング トークンの追加がオブジェクトの誤認識を減らすか?
- RQ4訓練データの構築(LVIS/COCO からのポリゴン)がスケッチと画像内容の整合性に与える影響は何か?
- RQ5分布外プロンプトや複数オブジェクトを含むシーンでのフレームワークの性能はどうか?
主な発見
- GPT-4 は空間的関係のベンチマークで、約97% の指示遵守精度を持つ compilable TikZ スケッチを生成できる。
- Control-GPT は最先端の空間精度を達成し、Stable Diffusion などのベースラインをほぼ2倍に近づける(Visor 指標で 44.2% 対 18.8% の Uncond)。
- ポリゴンスケッチとグラウンディング トークンを用いた ControlNet のファインチューニングは、コントローラの忠実度を改善し、オブジェクト同定エラーを減らす。
- Control-GPT は物体配置タスクで SOTA の性能を達成し、複数オブジェクトを含む複雑なシーンも OpenAI DALL-E 2 ら他のベースラインよりも優れて扱う。
- グラウンディング トークンは、スケッチを明示的なオブジェクト名と位置に結びつけることで曖昧さをさらに低減し、プロンプトと生成内容の整合性を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。