[論文レビュー] Cross-lingual Language Model Pretraining
本論文は、非教師あり(CLM/MLM)および教師あり(TLM)の事前学習を用いて多言語表現を学習するCross-lingual Language Models(XLM)を提案し、クロスリンガル分類および非監督・監督機械翻訳の双方で最先端の結果を達成する。
Recent studies have demonstrated the efficiency of generative pretraining for English natural language understanding. In this work, we extend this approach to multiple languages and show the effectiveness of cross-lingual pretraining. We propose two methods to learn cross-lingual language models (XLMs): one unsupervised that only relies on monolingual data, and one supervised that leverages parallel data with a new cross-lingual language model objective. We obtain state-of-the-art results on cross-lingual classification, unsupervised and supervised machine translation. On XNLI, our approach pushes the state of the art by an absolute gain of 4.9% accuracy. On unsupervised machine translation, we obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the art by more than 9 BLEU. On supervised machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.
研究の動機と目的
- クロスリンガルな事前学習が多言語の文表現を改善することを示す。
- モノリンガルデータに対する非教師ありのクロスリンガル目的(CLM、MLM)を提案する。
- 並列データを活用した教師ありのクロスリンガル目的(TLM)を導入する。
- XNLI、非教師付きMT、および教師付きMTで最先端の性能を示す。
- 低資源言語とクロスリンガル埋め込みの利点を強調する。
提案手法
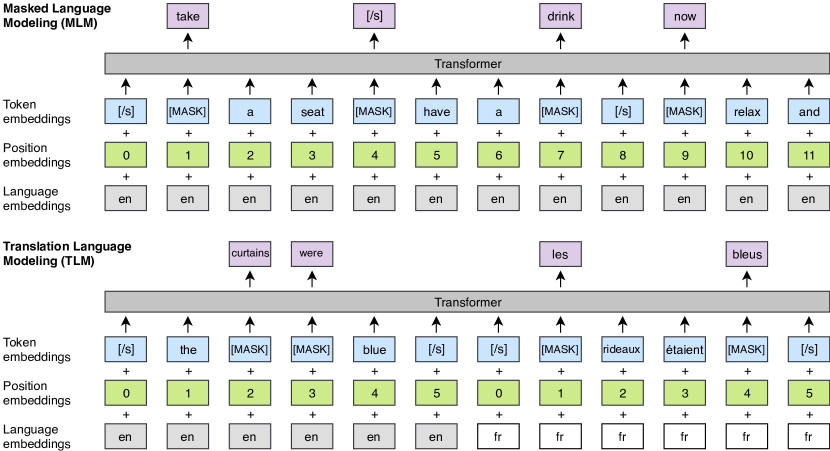
- N言語に跨るByte Pair Encodingで学習された共有のサブワード語彙を使用する。
- モノリンガルデータ上でCLMを用いて前文脈から語を予測するTransformer言語モデルを訓練する。
- トークンの15%をマスクして文脈から予測するMLMを、バッチあたり複数の文をストリーミングしながら訓練する。
- Translation Language Modeling (TLM) を導入し、並列文を連結してトークンをマスクし、ソースとターゲットの文脈の両方に注意を向けて表現を整列させられるようにする。
- 事前学習済みのXLMをクロスリンガル分類タスクにファインチューンするため、最初の隠れ状態に線形分類器を追加し、英語NLIデータで訓練しつつ15言語で評価する。
- エンコーダ/デコーダをさまざまな事前学習方式(EMB、CLM、MLM)で初期化し、デノイジング自己符号化とバック翻訳で訓練して非教師付きMTを評価する。
- CLM/MLMで事前学習し、WMT’16の Romanian-English で訓練して監督付きMTを評価する。
- 関連言語データを混在させた場合の低資源言語モデリングで困惑度が改善されることを示す。
実験結果
リサーチクエスチョン
- RQ1並列データなしで、非教師ありのクロスリンガル目的(CLM、MLM)は転移可能な多言語表現を生み出せるか?
- RQ2並列データを活用した教師ありのクロスリンガル目的(TLM)の組み込みは、クロスリンガル転送を改善するか?
- RQ3XLMの事前学習方法がクロスリンガル分類(XNLI)および機械翻訳(非教師付きおよび教師付き)にどう影響するか?
- RQ4クロスリンガル事前学習が低資源言語とクロスリンガル語彙埋め込みに与える影響は何か?
主な発見
- 非教師付きのMLMおよびMLM+CLMのベースラインは強力なクロスリンガル分類性能を達成し、MLM+TLMが大幅な改善をもたらす。
- XNLIでは、MLM+TLMが最先端の平均精度向上を達成(ゼロショット分類で過去のARTETXE/SOTAに対して最大で絶対4.9%の向上)。
- 非教師付きMTはMLM事前学習の恩恵を大きく受け、WMT’16のドイツ語-英語で34.3 BLEUに到達(従来の最先端を>9 BLEU上回る)。
- 教師付きMTは事前学習の恩恵を受け、 Romanian-English が38.5 BLEUに到達、従来のSOTAを>4 BLEU上回る。
- Cross-lingual pretrainingは Hindi/Englishデータを活用した場合 Nepaliの困惑度を改善する(例: Nepali+Hindi は 115.6 対 157.2)。
- XLM埋め込みはクロスリンガル語彙類似度指標(SemEval’17)でMUSEおよびConcatを上回り、より近い語翻訳ペアを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。