[論文レビュー] CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages
CulturaX は公開リリース済みの6.3兆トークン規模の多言語データセットで、167言語をカバーし、訓練の高品質な LLM に向けて広範囲にクリーンアップと重複排除が施されています。 HuggingFace で提供されています。
The driving factors behind the development of large language models (LLMs) with impressive learning capabilities are their colossal model sizes and extensive training datasets. Along with the progress in natural language processing, LLMs have been frequently made accessible to the public to foster deeper investigation and applications. However, when it comes to training datasets for these LLMs, especially the recent state-of-the-art models, they are often not fully disclosed. Creating training data for high-performing LLMs involves extensive cleaning and deduplication to ensure the necessary level of quality. The lack of transparency for training data has thus hampered research on attributing and addressing hallucination and bias issues in LLMs, hindering replication efforts and further advancements in the community. These challenges become even more pronounced in multilingual learning scenarios, where the available multilingual text datasets are often inadequately collected and cleaned. Consequently, there is a lack of open-source and readily usable dataset to effectively train LLMs in multiple languages. To overcome this issue, we present CulturaX, a substantial multilingual dataset with 6.3 trillion tokens in 167 languages, tailored for LLM development. Our dataset undergoes meticulous cleaning and deduplication through a rigorous pipeline of multiple stages to accomplish the best quality for model training, including language identification, URL-based filtering, metric-based cleaning, document refinement, and data deduplication. CulturaX is fully released to the public in HuggingFace to facilitate research and advancements in multilingual LLMs: https://huggingface.co/datasets/uonlp/CulturaX.
研究の動機と目的
- 大規模なオープン多言語データセットを提供して、LLM 訓練データの透明性と民主化を促進する。
- 多言語リソース(mC4 と OSCAR)の統合と更新を行い、英語以外の言語カバーを最大化する。
- 言語を超えて高品質な訓練データを保証するため、厳格なクリーンアップと重複排除を適用する。
- 167 言語にわたるすぐに利用可能なデータで、多言語LLMの研究開発を可能にする。
提案手法
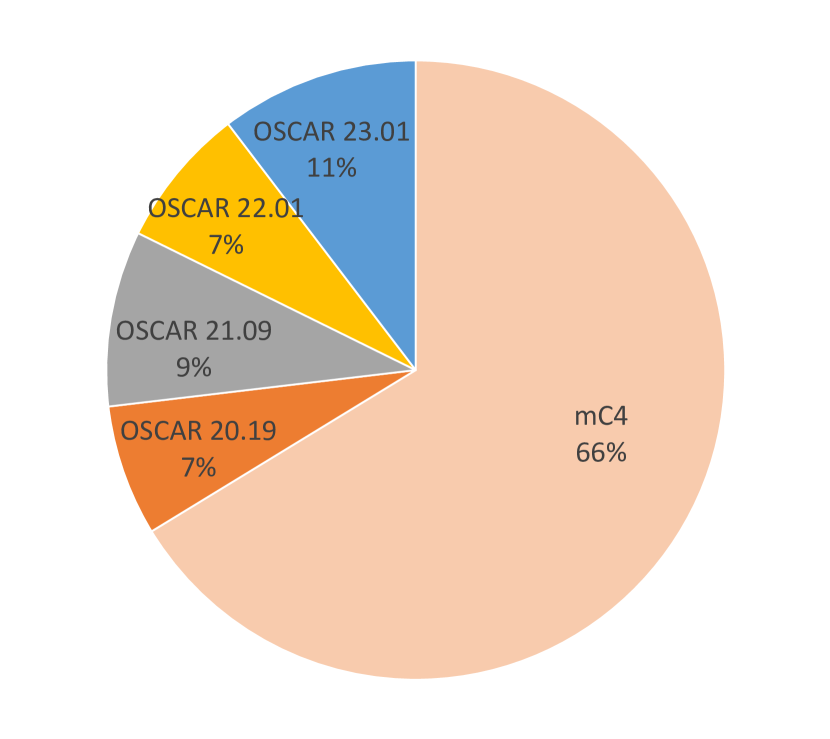
- 最新の mC4 (v3.1.0) を 2023.01 配布までの OSCAR コーパスと組み合わせる。
- 言語識別の再予測、URL ベースのフィルタリング、指標ベースのクレンジング、文書の精製を含む多段階のデータクリーニングパイプラインを適用する。
- フィルタリング閾値を決定するため、IQR の変種を用いた言語特有の閾値設定を実行する。
- 言語ごとに MinHashLSH を用いた文書レベルの重複排除と URL ベースの重複排除を実行する。
- 前処理と重複排除のために大規模な計算資源(600 台の AWS EC2 インスタンス)を活用する。
- 将来の研究を支援するため、KenLM モデルを公開する。
実験結果
リサーチクエスチョン
- RQ1CulturaX は167言語に跨る高品質なLLMの訓練に適した、スケーラブルで多言語の公開アクセス可能なデータセットを提供できるか?
- RQ2提案されたクリーニングと重複排除パイプライン(言語再予測、URLフィルタリング、指標ベースのフィルタリング、文書の精製、MinHashベースの重複排除)は、従来の公開データセットと比較して、著しく高品質な多言語コーパスを生み出すか?
- RQ3mC4 v3.1.0 と OSCAR を組み合わせ、厳密な多言語クリーニングを適用することによって、言語カバレッジ、サイズ、品質のトレードオフはどのようになるか?
主な発見
- CulturaX は 6.3 trillion tokens を 167 言語に跨って含み、LLM 訓練のための大規模な多言語リソースとなっている。
- 初期文書の 46% 以上がクリーニング/重複排除パイプラインを通じて削除され、品質の大幅な向上を示している。
- データセットは非英語コンテンツを重視しており、 multilingual training を支えるため、データの半数を超える量が非英語言語に割り当てられている。
- MinHashLSH を用いた文書レベルの重複排除と URL ベースの重複排除により、訓練データの冗長性と記憶化リスクを低減する。
- このパイプラインは言語識別の再予測(cld3 の代わりに FastText を使用)を用いて、言語ラベル付けの正確性とデータ品質を向上させる。
- HuggingFace に公開されており、再現性と多言語NLP研究での広範な利用を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。