[論文レビュー] Curiosity-driven Exploration for Mapless Navigation with Deep Reinforcement Learning
論文は intrinsic curiosity を Intrinsic Curiosity Module (ICM) によって DRL の mapless ナビゲーションに補強し、学習効率の向上と未知のマップへの一般化を示す。
This paper investigates exploration strategies of Deep Reinforcement Learning (DRL) methods to learn navigation policies for mobile robots. In particular, we augment the normal external reward for training DRL algorithms with intrinsic reward signals measured by curiosity. We test our approach in a mapless navigation setting, where the autonomous agent is required to navigate without the occupancy map of the environment, to targets whose relative locations can be easily acquired through low-cost solutions (e.g., visible light localization, Wi-Fi signal localization). We validate that the intrinsic motivation is crucial for improving DRL performance in tasks with challenging exploration requirements. Our experimental results show that our proposed method is able to more effectively learn navigation policies, and has better generalization capabilities in previously unseen environments. A video of our experimental results can be found at https://goo.gl/pWbpcF.
研究の動機と目的
- 環境マップが利用できない状況での mapless ロボットナビゲーションにおける効果的な探索を動機付ける。
- ポリシー学習を導くために intrinsic motivation を external rewards と統合する。
- 未知の環境や構造への学習ポリシーの一般化を評価する。
提案手法
- 外部報酬と内在的報酬信号を組み合わせた R = Re + liRi で拡張した A3C 強化学習を適用する。
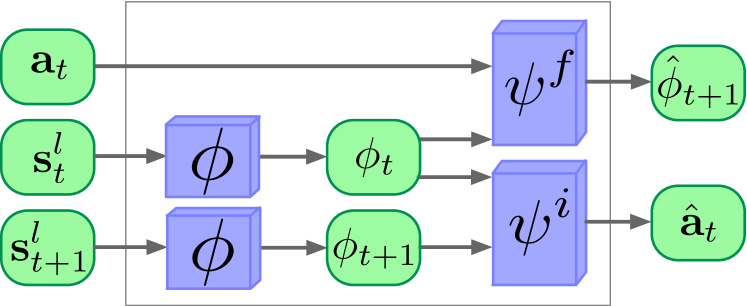
- Intrinsic Curiosity Module (ICM) は φ, inverse model ψi, forward model ψf で構成され、予測誤差から intrinsic reward Ri を生成する。
- 非同期アクター(A3C)を用いて外部報酬と内在的報酬の混合で訓練し、新規状態の探索を促進する。
- 状態としてレーザーレンジセンサーと相対ゴール姿勢を用い、アクションは離散的(直進、左折、右折)。
- ICM 損失は逆モデルのクロスエントロピーと前方モデルの回帰を組み合わせて φ を形成し、有用な表現を促進する。
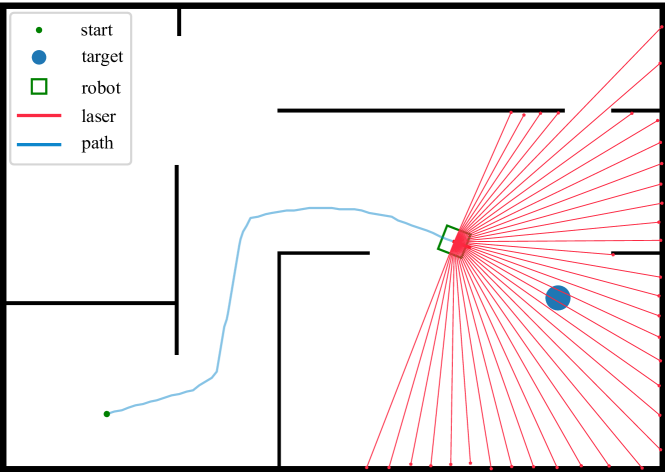
実験結果
リサーチクエスチョン
- RQ1intrinsic curiosity は mapless ナビゲーションにおける DRL のサンプル効率と収束を改善するか?
- RQ2異なるレイアウトを持つ未知の環境への一般化に、 intrinsic motivation はどのように影響するか?
- RQ3LSTM の有無、エントロピーの有無といった条件下で、好奇心主導の探索は標準的な探索より優れているか?
- RQ4内在報酬と外在報酬の間には、ナビゲーションポリシーを導く際のトレードオフは何か?
主な発見
| 探索戦略 | Map1 の成功率 (%) | Map1 のステップ数(平均 ± 標準偏差) |
|---|---|---|
| A3C- | 88.3 | 173.063 ± 123.277 |
| Entropy | 96.7 | 102.220 ± 90.230 |
| ICM | 98.7 | 91.230 ± 62.511 |
| ICM+Entropy | 100 | 75.160 ± 52.075 |
- ICM に基づく探索は、訓練マップでエントロピーのみまたは無好奇心のベースラインより、成功率が高く、しばしば経路長が短い。
- Map1 で ICM は 98.7% の成功率、平均 91.2 ステップ(標準偏差 62.5)を達成したのに対し、最も強力な非ICMベースラインは 88.3% と 173.1 ステップであった。
- 組み合わせ ICM とエントロピーはさらに性能と安定性を向上させ、Map1 で LSTM 使用時に平均 75.2 ステップ、標準偏差 52.1、100% の成功を達成。
- ICM は未知マップ(Map2–4)への一般化を改善し、特により困難なレイアウトで、ICM+Entropy はしばしば他手法より良いまたは同等の成功と低いステップ数を示す。
- 結果は好奇心が局所最小値を脱し、情報量の多い状態へ agent を誘導することで学習を加速するのに役立つことを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。