[論文レビュー] Curriculum Learning Meets Directed Acyclic Graph for Multimodal Emotion Recognition
MultiDAG+CL は、マルチモーダル DAG ベースの融合と curriculum learning を組み合わせて、IEMOCAP および MELD における会話の感情認識を改善し、感情シフトとデータ不均衡に対処します。
Emotion recognition in conversation (ERC) is a crucial task in natural language processing and affective computing. This paper proposes MultiDAG+CL, a novel approach for Multimodal Emotion Recognition in Conversation (ERC) that employs Directed Acyclic Graph (DAG) to integrate textual, acoustic, and visual features within a unified framework. The model is enhanced by Curriculum Learning (CL) to address challenges related to emotional shifts and data imbalance. Curriculum learning facilitates the learning process by gradually presenting training samples in a meaningful order, thereby improving the model's performance in handling emotional variations and data imbalance. Experimental results on the IEMOCAP and MELD datasets demonstrate that the MultiDAG+CL models outperform baseline models. We release the code for MultiDAG+CL and experiments: https://github.com/vanntc711/MultiDAG-CL
研究の動機と目的
- 会話におけるマルチモーダル感情認識を、テキスト、オーディオ、視覚的手がかりを DAG ベースの融合フレームワークを用いて前進させる。
- ERC における感情シフトとデータ不均衡の課題を緩和するために Curriculum Learning を組み込む。
- 標準的な ERC ベンチマーク(IEMOCAP および MELD)で最先端の性能を示す。
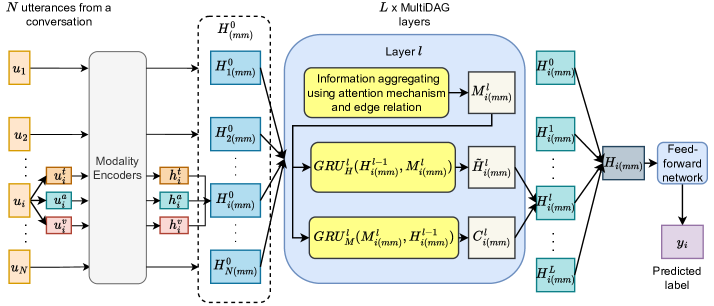
提案手法
- テキスト: BiLSTM、オーディオ/視覚: FC など、モダリティ別エンコーダで Utterances を表現する。
- 情報が過去の utterances からのみ流れるように、Directed Acyclic Graph (DAG-GNN) を用いてモダリティを融合する。
- アテンションベースの inter-utterance edges を計算し、layer-wise GRUs で集約して最終的な utterance embeddings を取得する。
- 感情シフトに基づく Difficult Measure Function (DMF) を用いた Curriculum Learning を導入し、トレーニング buckets の連続性を作る。
- より難しい会話を徐々に導入する bucket-based curriculum schedule で訓練する。
- 各 utterance の感情ラベルを予測するためのクロスエントロピー損失で最適化する。
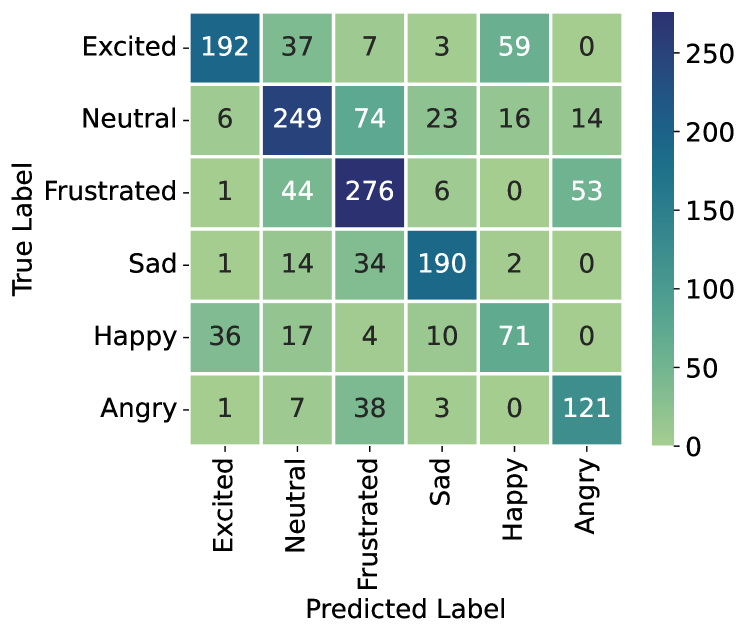
実験結果
リサーチクエスチョン
- RQ1DAG-based fusion of textual, acoustic, and visual features は unimodal および他のマルチモーダルベースラインより ERC の性能をどのように向上させるか?
- RQ2感情シフトダイナミクスに合わせた Curriculum Learning はデータ不均衡と感情の移動に対処する ERC モデルに有効か?
- RQ3実世界データセット(IEMOCAP、MELD)におけるモダリティの組み合わせは ERC の性能にどのような影響を与えるか?
主な発見
- MultiDAG+CL は、従来のマルチモーダル ERC 手法と比較して IEMOCAP および MELD で最先端の性能を達成。
- Curriculum Learning は感情認識の精度を向上させ、特に Sad、Neutral、Angry クラスでの性能向上と Neutral の Disgust への誤分類を抑制。
- CL バケツの最適な数はデータセットによって異なる(IEMOCAP: 5 buckets; MELD: 12 buckets)。
- Textual modality は unimodal の中で最も強力であり、Text+Audio の組み合わせが最良の二値モーダル性能を頻繁にもたらすことが多い;Visual modality はノイズに脆弱。
- MultiDAG+CL は Neutral による Disgust への誤分類を IEMOCAP で 19.3% から 12.3% に低減。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。