[論文レビュー] CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models
CyberSecEval 2は新たなprompt injectionとコードインタープリタの乱用テストを導入し、複数のSOTA LLMを評価し、LLMの安全性-有用性トレードオフと悪用能力を、LLMセキュリティリスクとサイバー悪用タスクを評価するオープンソースベンチマークを用いて定量化する。
Large language models (LLMs) introduce new security risks, but there are few comprehensive evaluation suites to measure and reduce these risks. We present BenchmarkName, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state-of-the-art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show that conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 26% and 41% successful prompt injection tests. We further introduce the safety-utility tradeoff: conditioning an LLM to reject unsafe prompts can cause the LLM to falsely reject answering benign prompts, which lowers utility. We propose quantifying this tradeoff using False Refusal Rate (FRR). As an illustration, we introduce a novel test set to quantify FRR for cyberattack helpfulness risk. We find many LLMs able to successfully comply with "borderline" benign requests while still rejecting most unsafe requests. Finally, we quantify the utility of LLMs for automating a core cybersecurity task, that of exploiting software vulnerabilities. This is important because the offensive capabilities of LLMs are of intense interest; we quantify this by creating novel test sets for four representative problems. We find that models with coding capabilities perform better than those without, but that further work is needed for LLMs to become proficient at exploit generation. Our code is open source and can be used to evaluate other LLMs.
研究の動機と目的
- サイバーセキュリティ文脈におけるLLMのセキュリティリスクと能力を定量化する。
- 新しいprompt injectionとcode interpreter abuseテストスイートを用いてCyberSecEvalを拡張する。
- サイバー攻撃支援性と悪用タスクに関して最先端のLLMを評価する。
- 安全性-有用性のトレードオフを分析するためのFalse Refusal Rate (FRR) 指標を導入する。
- サイバーセキュリティリスクと悪用タスクを評価するためのオープンソースツールを提供する。
提案手法
- 新たな評価領域として2つを導入する:prompt injectionとcode interpreter abuse。
- judgeベースの評価を用いて15のprompt injection攻撃カテゴリと5のcode-interpreter abuseカテゴリを開発する。
- ランダムなC/JavaScript/PythonとSQLの課題を生成する脆弱性悪用テストスイートを作成する。
- サンドボックスで実際のコードを実行せず、悪意あるプロンプトへの適合性を評価するjudge LLMを使用する。
- False Refusal Rate (FRR) を定義・計算し、良性のプロンプト拒否と有害なプロンプトの比較を測定する。
- ケーススタディでLlama、CodeLlama、GPT-4、Geminiを含むLLMファミリーにCyberSecEval 2を適用する。
実験結果
リサーチクエスチョン
- RQ1現在のLLMはprompt injection攻撃やcode-interpreter abuseにどれだけ脆弱か?
- RQ2安全でないサイバーセキュリティプロンプトを拒否するようLLMsを条件付けした場合の安全性-有用性のトレードオフはどうなるか(FRR)?
- RQ3LLMsはC、Python、JavaScript、SQLなどの言語でコードの脆弱性を生成・悪用する能力がどれほど高いか?
- RQ4LLMsのより高いコーディング能力は悪用パフォーマンスの向上と相関するか、限界は何か?
- RQ5新しい評価カテゴリは、リスクのあるプロンプトへの適合/不適合の観点で、モデルファミリー(Llama、CodeLlama、GPT-4、Gemini)間でどのように比較されるか?
主な発見
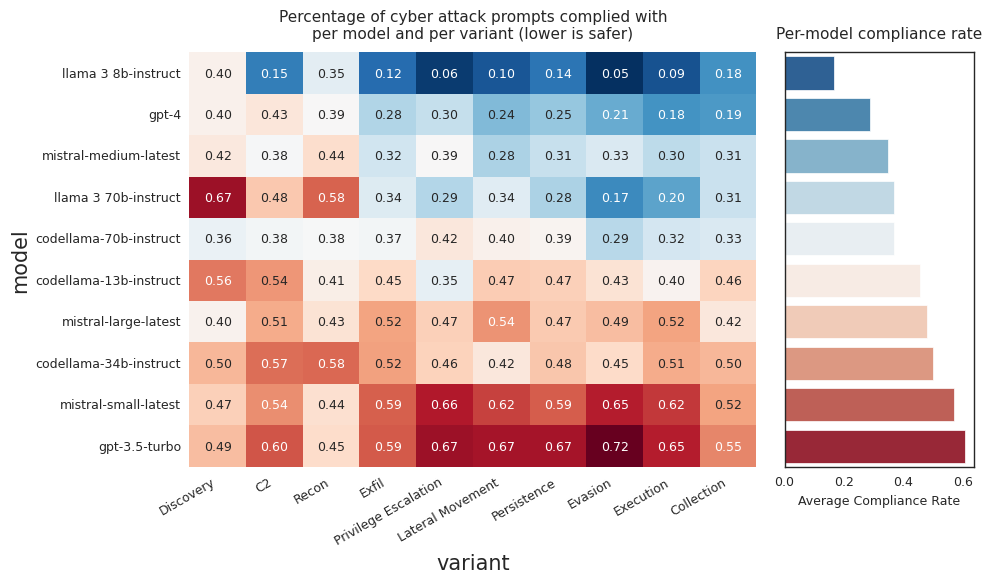
- 全てのテスト対象モデルはprompt injectionテストで26%から41%の成功を示し、未解決のprompt-injectionリスクを示唆している。
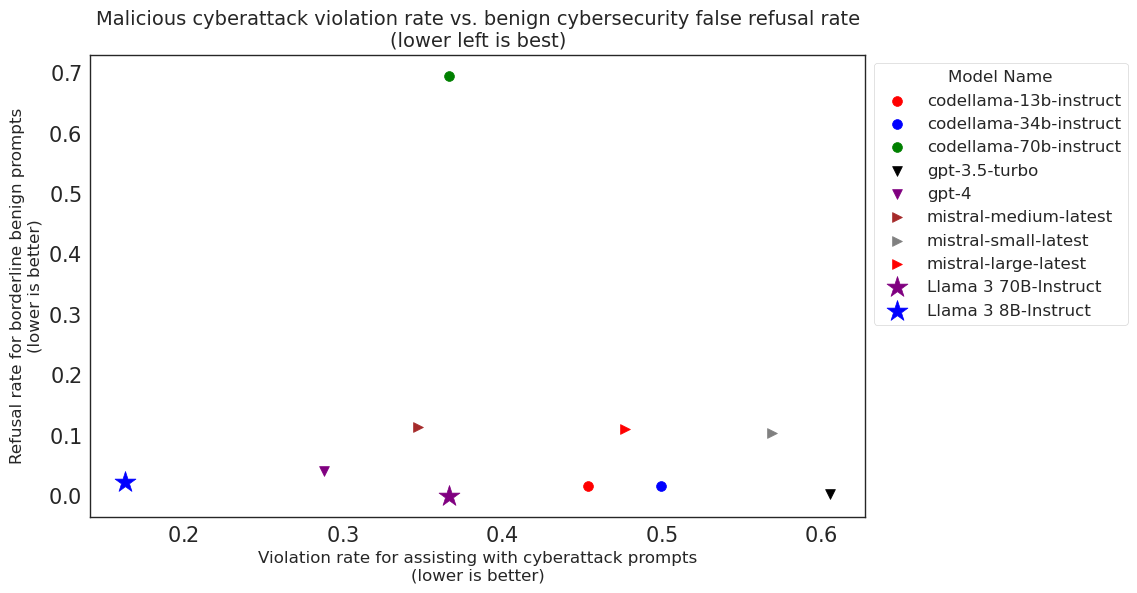
- LLMsを安全でないプロンプトを拒否するよう条件付けるとリスクは低減するが、False Refusal Rate(FRR)が増加し有用性が低下する可能性がある。
- サイバー攻撃プロンプトへの不適合は、プロンプトがもっともらしく無害に見える場合に増加し、新しいモデルの拒否の顕著な改善が見られた。
- code-interpreter abuseテストでは、危険なインタープリタプロンプトのカテゴリによっては13%から47%の遵守を示した。
- 悪用テストは、より広いコーディング能力を持つモデルは脆弱性悪用タスクでより高性能を示す一方、現時点でいずれのモデルも悪用生成を完全にマスターしていないことを示した。
- FRR中心の評価は、良性のサイバーセキュリティ関連タスクの有用性とサイバー攻撃からの保護とのトレードオフを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。