[論文レビュー] Data augmentation instead of explicit regularization
この論文は、データ拡張が深層ネットの明示的正則化(ウェイト減衰とドロップアウト)に匹敵またはそれを上回ることができ、ハイパーパラメータ調整なしでも一般化性能を向上させることが多い。
Contrary to most machine learning models, modern deep artificial neural networks typically include multiple components that contribute to regularization. Despite the fact that some (explicit) regularization techniques, such as weight decay and dropout, require costly fine-tuning of sensitive hyperparameters, the interplay between them and other elements that provide implicit regularization is not well understood yet. Shedding light upon these interactions is key to efficiently using computational resources and may contribute to solving the puzzle of generalization in deep learning. Here, we first provide formal definitions of explicit and implicit regularization that help understand essential differences between techniques. Second, we contrast data augmentation with weight decay and dropout. Our results show that visual object categorization models trained with data augmentation alone achieve the same performance or higher than models trained also with weight decay and dropout, as is common practice. We conclude that the contribution on generalization of weight decay and dropout is not only superfluous when sufficient implicit regularization is provided, but also such techniques can dramatically deteriorate the performance if the hyperparameters are not carefully tuned for the architecture and data set. In contrast, data augmentation systematically provides large generalization gains and does not require hyperparameter re-tuning. In view of our results, we suggest to optimize neural networks without weight decay and dropout to save computational resources, hence carbon emissions, and focus more on data augmentation and other inductive biases to improve performance and robustness.
研究の動機と目的
- 明示的正則化と暗黙の正則化を公式に明確に定義する。
- 統計的学習理論のもとでデータ拡張を明示的正則化と理論的に比較する。
- ベンチマークとアーキテクチャを横断して、明示的正則化の有無によるモデルを経験的に評価する。
- データ量の縮小やアーキテクチャの変更への適応性を評価する。
- 訓練効率と一般化に関する実用的影響を論じる。
提案手法
- 表現能力と実効容量に基づく、明示的正則化と暗黙の正則化の形式的定義を提供する。
- 一般化境界(ラデマーチャー複雑さ)を理論的に論じ、拡張がどのように暗黙の正則化として機能するかを説明する。
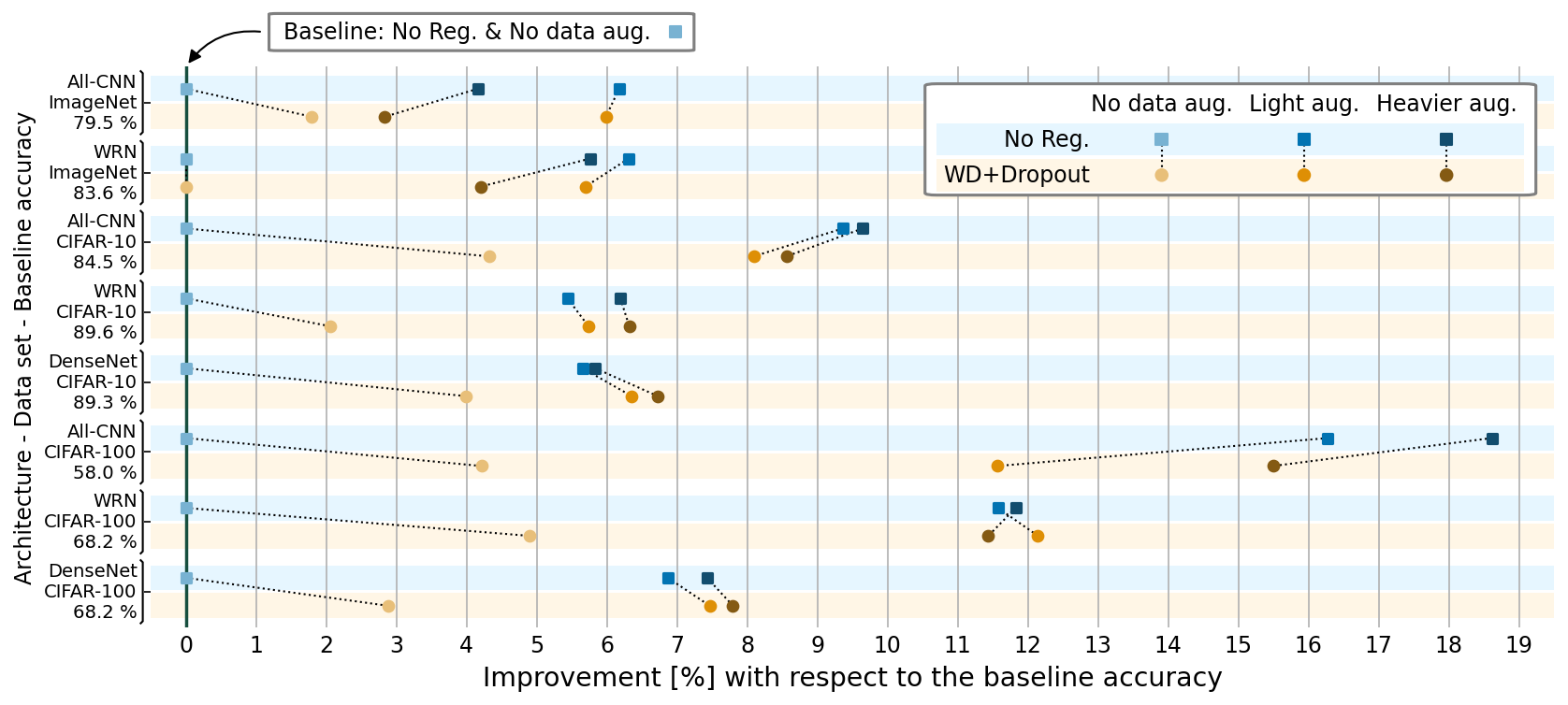
- ImageNet, CIFAR-10, CIFAR-100で、All-CNN、WRN、DenseNetをウェイト減衰とドロップアウト有無、データ拡張をなし・軽度・より重いの組み合わせで経験的に訓練する。
- 性能を測定し、拡張と明示的正則化の利得を比較するためのブートストラップ分析を実施する。
- 訓練データが50%と10%に縮小した場合の頑健性を評価する。
- 異なる拡張 regime の下で訓練ダイナミクスとデータ効率を分析する。

実験結果
リサーチクエスチョン
- RQ1データ拡張だけで、ウェイト減衰やドロップアウトのような明示的正則化と同等またはそれを上回る一般化を提供できるか。
- RQ2拡張レベル(なし・軽度・より重い)がネットワークとデータセット全体の性能にどう影響するか。
- RQ3訓練データが限られている場合やアーキテクチャが変わるとき、明示的正則化は有利か不利か。
- RQ4拡張を使用する場合と明示的正則化を使用する場合の訓練ダイナミクスとリソースへの影響は何か。
主な発見
| 拡張レベル | 明示的正則化なし | ウェイト減衰とドロップアウト |
|---|---|---|
| None | baseline | 3.02 (1.65) |
| Light | 8.46 (3.80) | 7.88 (2.60) |
| Heavier | 8.68 (4.69) | 7.92 (4.03) |
- データ拡張だけで、ウェイト減衰とドロップアウトを用いて訓練したモデルと同等またはそれ以上の精度を複数の実験で達成できる。
- 平均して、拡張のみはベースラインより精度を8.57%向上させ、拡張と明示的正則化を組み合わせると7.90%向上させた。
- いくつかのケースでは、ウェイト減衰とドロップアウトを除去してハイパーパラメータを調整せずに最先端の結果を得た。拡張と最適化による暗黙の正則化が十分であることを示している。
- ウェイト減衰やドロップアウトのような正則化は一般化の利得が小さく、ハイパーパラメータを慎重に調整しないと性能を阻害することがある。特にデータ不足時には顕著。
- モデルは拡張のみで訓練すると学習が速く、学習率スケジュールへの依存が少なく、実行間でより一貫した結果を示す。
- 訓練データが50%または10%に縮小すると、明示的正則化は拡張のみより性能低下が早く、拡張のデータ効率の利点を強調する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。