[論文レビュー] Data Decisions and Theoretical Implications when Adversarially Learning Fair Representations
本論文は対向的学習を用いて、推論時に機微属性へアクセスせずに公正な潜在表現を学習し、敵対的データ分布が公正性の定義をどう形作るかと、小さくバランスの取れた敵対的データセットが公平性を実質的に改善できる一方、精度とのトレードオフが生じることを示す。
How can we learn a classifier that is "fair" for a protected or sensitive group, when we do not know if the input to the classifier belongs to the protected group? How can we train such a classifier when data on the protected group is difficult to attain? In many settings, finding out the sensitive input attribute can be prohibitively expensive even during model training, and sometimes impossible during model serving. For example, in recommender systems, if we want to predict if a user will click on a given recommendation, we often do not know many attributes of the user, e.g., race or age, and many attributes of the content are hard to determine, e.g., the language or topic. Thus, it is not feasible to use a different classifier calibrated based on knowledge of the sensitive attribute. Here, we use an adversarial training procedure to remove information about the sensitive attribute from the latent representation learned by a neural network. In particular, we study how the choice of data for the adversarial training effects the resulting fairness properties. We find two interesting results: a small amount of data is needed to train these adversarial models, and the data distribution empirically drives the adversary's notion of fairness.
研究の動機と目的
- 推論時に敏感属性が利用できない、または訓練時にラベル付けが難しい場合に、公正な予測を学習する動機づけ。
- 敵対的目的のデータ分布と公正性の定義を結びつける。
- 敵対的データがどれくらい必要か、そしてその分布が公正性の結果に与える影響を実証的に評価する。
- 異なる敵対的データ regime の下で、モデルの精度と公正性のトレードオフを示す。
提案手法
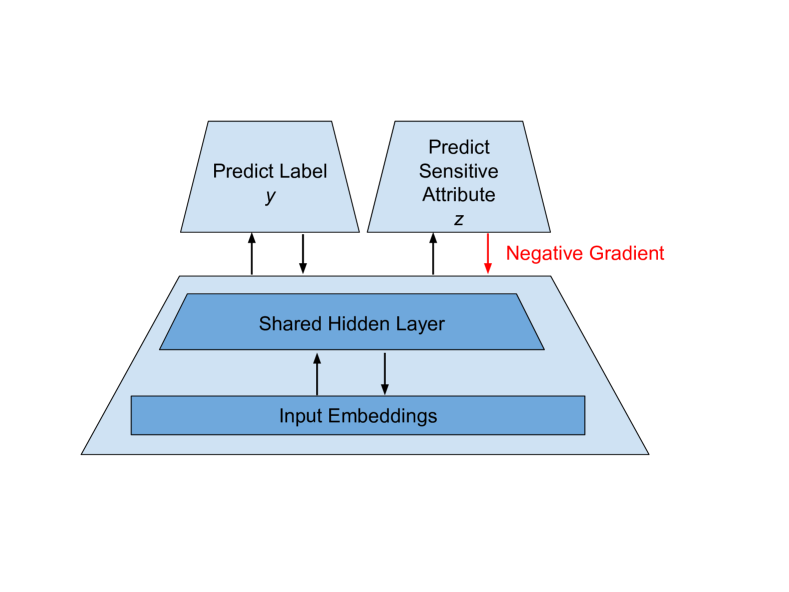
- Yを予測する一つのヘッドと、敵対者が latent g(X) から Z を予測しようとするマルチヘッドニューロンルネットワークを提案する。
- Yを適切に予測できるようにしつつ、g(X) が Z に関する情報を隠すよう negative-gradient trick を J_lambda を介して導入する。
- 敵対者が使用するデータセット S と、それが Y と Z の分布に基づいて公正性特性へどう影響するかを分析する。
- 公正性指標と表現の影響を研究するために、S のサイズと分布を変化させて実験する。
実験結果
リサーチクエスチョン
- RQ1敵対的学習データ S の選択と分布が、モデルの得る公正性にどのように影響するか?
- RQ2敵対的訓練で敏感属性 Z の分布を均等化した場合と非均等化の場合で、公正性と精度にどのような影響があるか?
- RQ3意味のある公正性の改善を達成するには、どれくらいの敵対的データが必要か、精度を過度に犠牲にせずに?
- RQ4主ラベル Y の分布(income)を変えると、学習された表現の機会平等性と人口統計的平等性にどう影響するか?
主な発見
| 男性 | 女性 |
|---|---|
| 15128 | 9592 |
| 6662 | 1179 |
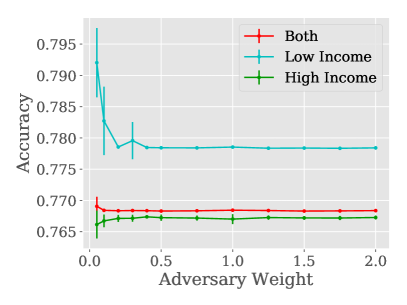
- バランスの取れた敵対データは、公正性指標を大幅に改善し、トレーニングを安定させる一方で、精度にはコストがかかる。
- 敵対データ分布が高所得群または低所得群と対応すると、それぞれの群に対する機会均等性に特化した改善をもたらし、群を混ぜると各指標で公正性が向上する。
- 非常に小さな敵対データセット(例: 500例程度)でも意味のある公正性の改善を生み出せる。
- 敵対データの主ラベル Y の分布は、データ選択と公正性の定義を結びつける理論的期待と一致して、異なる公正性の結果を促す。
- 敵対訓練におけるZの分布を均等にすると、通常は自然分布からのランダムサンプリングよりも強い公正性の効果が得られる。
- トレードオフがある:公正性を強化すると予測精度が低下することがあり、lambda の調整がこのバランスを mediating する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。