[論文レビュー] DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
DatasetDMは、拡散モデルの潜在コードからピクセル単位のアノテーションを抽出する知覚デコーダを使用するテキスト-to-データパラダイムを提示し、デコーダの訓練には約100枚の実画像のみで無限の合成ラベルデータを可能にします。
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
研究の動機と目的
- 知覚タスクにおける大規模なラベル付きデータの必要性を喚起し、ラベリングコストを削減する。
- 複数のタスクに跨る拡散潜在コードを知覚アノテーションにデコードする汎用フレームワークを提案する。
- 拡散反転と統一P-デコーダを活用して、多様なデータセットに対するテキスト指向データ生成を可能にする。
- 合成データがセグメンテーション、深度、ポーズタスクで最先端または競争力のある結果を達成できることを示す。
提案手法
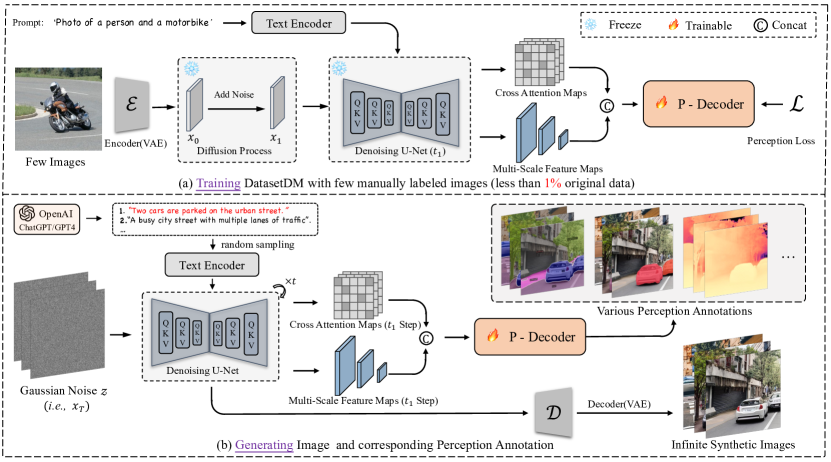
- 実画像から潜在コードを抽出するために拡散反転を用い、マルチスケールの拡散特徴とクロスアテンションマップを融合してハイパーカラム表現を形成する。
- 融合した拡散表現をさまざまな知覚アノテーション(マスク、深度、キーポイントなど)に変換する汎用的な知覚デコーダ(P-Decoder)を、トランスフォーマーに基づくアーキテクチャ内に開発する。
- 出力追従能力を誘導する視覚的アライン/インストゥルクトチューニング手法を用いて、実データラベルの1%未満でP-Decoderを訓練する。
- GPT-4を用いたテキスト指向データ生成を実行して多様なプロンプトを作成し、広範でオープンエンドなデータ合成パイプラインを可能にする。
- データ合成中は拡散モデルの重みを固定し、潜在コードの反転とデコーダを用いて合成アノテーションを生成し、無制限のアノテーションデータを可能にする。
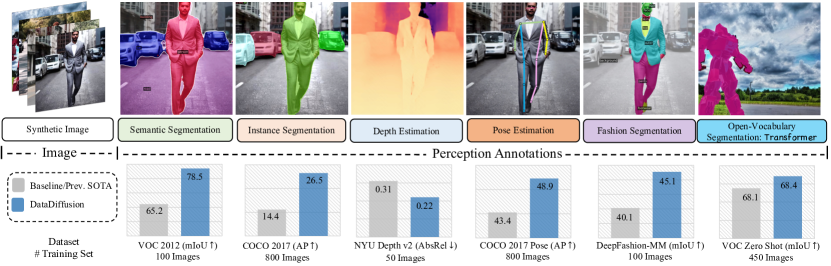
実験結果
リサーチクエスチョン
- RQ1統一された知覚デコーダは拡散潜在コードをデコードして、複数のタスクにわたって正確な知覚アノテーションを生成できるか?
- RQ2このデコーダを訓練して無限の合成ラベルデータを有効にするには、実データラベルがどれくらい必要か?
- RQ3拡散モデルによるテキスト指向データ生成は、セマンティックセグメンテーション、インスタンスセグメンテーション、深度推定、ポーズ推定などの下流知覚タスクを改善するか?
- RQ4拡散の時間ステップ、クロスアテンションの融合、プロンプトの多様性は、合成アノテーションの品質と有用性にどのような影響を与えるか?
主な発見
- DatasetDMによって生成された合成データはタスク全般で大幅な改善をもたらす。例として VOC 2012のセマンティックセグメンテーションで13.3%のmIoU向上、COCO 2017のインスタンスセグメンテーションで12.1%のAP向上。
- 実データ100枚のみを用いて合成データを組み合わせると、VOC 2012のmIoUは78.5%に達する(表2の文脈で実データのみのベースライン65.2%と比較)。
- COCO2017のインスタンスセグメンテーションで、800枚の実画像と80k枚の合成画像を用いて26.5 APを達成(表3より)。
- 深度推定とポーズ推定も恩恵を受け、合成データで訓練した場合に測定可能な改善が見られる(例:NYU Depth V2の深度は小規模な実データセットで約10%向上、ポーズ推定はベースラインを顕著に上回る増加)。
- ゼロショットおよび長尾分布のセグメンテーションタスクは合成データの恩恵を受け、ゼロショット/長尾設定で最大約20%のmIoU改善が報告されている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。