[論文レビュー] Decoder-Only or Encoder-Decoder? Interpreting Language Model as a Regularized Encoder-Decoder
この論文は、デコーダーのみの言語モデルを用いた seq2seq タスクを Regularized Encoder-Decoder (RED) フレームワークで分析し、注意機構の退化を特定し、Partial Attention Language Model (PALM) を提案して翻訳、要約、データ-to-text タスクで性能を向上させる。
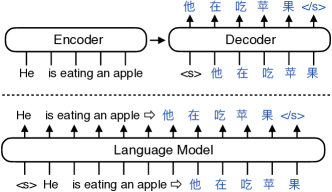
The sequence-to-sequence (seq2seq) task aims at generating the target sequence based on the given input source sequence. Traditionally, most of the seq2seq task is resolved by the Encoder-Decoder framework which requires an encoder to encode the source sequence and a decoder to generate the target text. Recently, a bunch of new approaches have emerged that apply decoder-only language models directly to the seq2seq task. Despite the significant advancements in applying language models to the seq2seq task, there is still a lack of thorough analysis on the effectiveness of the decoder-only language model architecture. This paper aims to address this gap by conducting a detailed comparison between the encoder-decoder architecture and the decoder-only language model framework through the analysis of a regularized encoder-decoder structure. This structure is designed to replicate all behaviors in the classical decoder-only language model but has an encoder and a decoder making it easier to be compared with the classical encoder-decoder structure. Based on the analysis, we unveil the attention degeneration problem in the language model, namely, as the generation step number grows, less and less attention is focused on the source sequence. To give a quantitative understanding of this problem, we conduct a theoretical sensitivity analysis of the attention output with respect to the source input. Grounded on our analysis, we propose a novel partial attention language model to solve the attention degeneration problem. Experimental results on machine translation, summarization, and data-to-text generation tasks support our analysis and demonstrate the effectiveness of our proposed model.
研究の動機と目的
- エンコーダ-デコーダアーキテクチャとデコーダーのみ言語モデルを seq2seq タスクで丁寧に比較する動機付け。
- デコーダーのみモデルにおける注意機構の退化問題と、それがソース注意に与える影響の特徴づけ。
- 公正な比較を可能にする正則化エンコーダ-デコーダ(RED)フレームワークを開発し、その構成要素を分析。
- PALM を提案して退化を緩和しつつ LM の利点を活用。
- 機械翻訳、要約、データ-to-text ジェネレーションのデータセットで PALM を実証的に検証。
提案手法
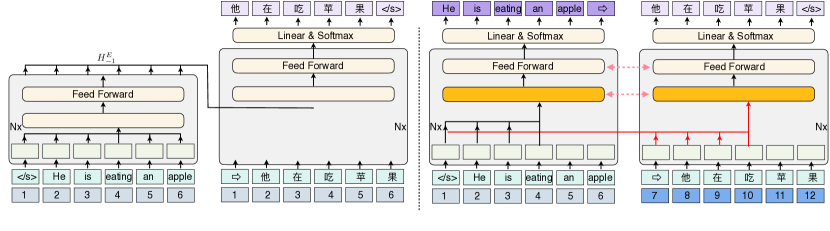
- 公平な比較のために encoder を用いた LM の挙動を再現する正則化エンコーダ-デコーダ(RED)フレームワークを定義。
- unidirectional cross attention を導入、Source Auto-Encoder (SAE)、パラメータ共有、層ごとの協調、連続的位置エンコーディングを導入して RED 内で LM の挙動を模倣。
- 注意機構の感度(ヤコビアン境界)を理論的に分析し、単方向クロスアテンションにおける退化を説明。
- PALM は、ソースに焦点を当てた PA アテンション分岐を追加し、生成長に対して固定、双方向ソースアテンションと別個の位置エンコーディングを使用して退化を緩和する。
- PALM の変種とアブレーション(例: PALM w/o SAE)を提供して構成要素の影響を切り分け。
- MT、要約、データ-to-text タスクを標準指標(BLEU、ROUGE、METEOR、CIDEr、NIST)で評価。
実験結果
リサーチクエスチョン
- RQ1デコーダーのみ LM アーキテクチャは seq2seq タスクで ED を本質的に下回るのか、それとも正則化された LM 風の構造がギャップを埋められるのか?
- RQ2LM ベースの seq2seq モデルにおける注意の退化は何が原因で、生成ステップごとにソース注意の感度へどう影響するのか?
- RQ3PALM アーキテクチャは退化を緩和しつつ LM の利点を維持できるのか?
- RQ4RED/PALM の変種は、ED および LM のベースラインと比較して MT、要約、データ-to-text のベンチマークでどう機能するか?
主な発見
| モデル | De-En | En-De | It-En | En-It | En-Fr | Es-En | En-Es | Ru-En | En-Ru | He-En | En-He | Ro-En | En-Ro | 平均 | パラメータ数 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ED | 34.18 | 28.00 | 31.96 | 29.42 | 40.86 | 40.99 | 37.53 | 23.09 | 18.20 | 38.09 | 25.41 | 38.14 | 28.30 | 31.86 | 47.1M |
| LM | 33.19 | 26.43 | 30.92 | 28.64 | 39.16 | 39.33 | 36.67 | 22.25 | 17.53 | 34.81 | 24.35 | 35.51 | 27.02 | 30.45 | 29.3M |
| LM-SPE | 33.35 | 27.35 | 31.36 | 28.87 | 39.93 | 39.69 | 36.99 | 21.89 | 17.98 | 34.89 | 24.80 | 35.19 | 27.72 | 30.77 | 29.3M |
| LM-LE | 33.58 | 27.46 | 31.38 | 29.03 | 40.14 | 39.87 | 37.05 | 22.24 | 18.08 | 34.80 | 24.31 | 35.76 | 27.96 | 30.90 | 29.3M |
| LM-PA | 34.54 | 28.35 | 32.01 | 29.70 | 40.15 | 40.58 | 37.24 | 22.98 | 18.45 | 35.64 | 25.37 | 37.35 | 28.02 | 31.57 | 35.6M |
| PreLM | 33.90 | 27.88 | 31.77 | 29.35 | 40.53 | 40.41 | 37.46 | 22.80 | 18.11 | 35.96 | 24.78 | 37.55 | 28.11 | 31.43 | 29.3M |
| PALM | 34.73 | 28.59 | 32.22 | 29.83 | 40.31 | 40.91 | 37.61 | 23.27 | 18.74 | 37.00 | 25.29 | 37.59 | 28.75 | 31.91 | 35.6M |
| PALM w/o SAE | 34.03 | 28.30 | 31.83 | 29.42 | 39.87 | 40.65 | 37.25 | 22.21 | 17.92 | 37.06 | 24.89 | 37.09 | 28.40 | 31.46 | 35.6M |
- LMは注意の退化により ED を下回る。生成ステップが進むにつれソースへの注意が減る。
- 理論的な上界は、単方向クロスアテンションがターゲットが大きくなるにつれてソース入力への感度が小さくなることを示し、退化を説明する。
- PALM は、生成長に依存せず固定される PA アテンション経路を追加し、双方向のソースアテンションと別個の位置エンコーディングを用いることで退化を緩和。
- PALM は一貫して LM および LM バリアントを上回り、報告されたベンチマークで ED の性能に近づくまたは上回る。
- PALM は IWSLT’14 の平均 BLEU を LM-PA ベースライン(31.57)および ED(31.86)より高い 31.91 を達成(表1)。さらに WebNLG、E2E、XSUM データセットで METEOR、ROUGE-L、CIDEr、NIST の指標が有利に改善(表4-6)。
- Ablations は SAE が性能に寄与することを示し、PALM w/o SAE は LM レベルへ結果を低下。
- このアプローチは ED および LM ベースラインに比べてパラメータ数を削減しつつ、優れたまたは競合する性能を提供。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。