[論文レビュー] Deductive Verification of Chain-of-Thought Reasoning
論文は Natural Program を導入し、自然言語の演繹推論フォーマットを用いて LLM の各推論ステップの検証を逐次可能にし、Unanimity-Plurality Voting スキームと組み合わせて chain-of-thought 推論の厳密さ、信頼性、解釈性を向上させる。算術と常識データセットの評価では、 premise-minimized な逐次検証で検証精度が高く、最終回答は多くの場合同等かそれ以上、完全検証を適用することで時に僅かに低下することもある。
Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inadvertently introduce hallucinations and accumulated errors, thereby limiting models' ability to solve complex reasoning tasks. Inspired by how humans engage in careful and meticulous deductive logical reasoning processes to solve tasks, we seek to enable language models to perform explicit and rigorous deductive reasoning, and also ensure the trustworthiness of their reasoning process through self-verification. However, directly verifying the validity of an entire deductive reasoning process is challenging, even with advanced models like ChatGPT. In light of this, we propose to decompose a reasoning verification process into a series of step-by-step subprocesses, each only receiving their necessary context and premises. To facilitate this procedure, we propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. By integrating this verification process into each deductive reasoning stage, we significantly enhance the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks. Code will be released at https://github.com/lz1oceani/verify_cot.
研究の動機と目的
- LLMs における厳密な演繹推論を動機づけ・実現し、Chain-of-Thought の幻覚( hallucinations)とエラーを減らす。
- 検証性を高めるために推論ステップごとに最小限の前提を明示的に列挙する Natural Program フォーマットを提案。
- 推論のための最小限の文脈だけを分析して逐次検証を開発し、投票と統合して最終回答の信頼性を向上。
- GPT-3.5-turboを用いた多様な推論ベンチマークでこのアプローチを実証的に検証し、厳密さと解釈性を向上させる。
提案手法
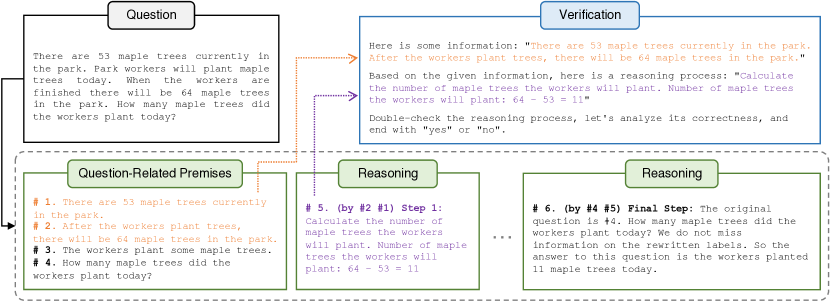
- Natural Program を導入: 質問に関連する前提と明示的な前提使用を伴う逐次的推論をリスト化する構造化された自然言語フォーマット。
- 最小限の必要な前提 p_i を用いて個々のステップの有効性 V(s_i) を分解し、局所検証を可能にする。
- 前提とステップ記述、検証指示を含むプロンプトで単一ステップの有効性チェックを実行し、信頼性のためにワンショットプロンプトを使用する。
- Unanimity-Plurality Voting (UPV) を適用: 総意フェーズで全ステップが有効なチェーンをフィルタリングし、続いて多数決投票が検証済みチェーンの中から最終解を決定。
- 2つのレジームを評価: (i) 完全検証なしの Natural Program 推論, (ii) 演繹検証と UPV を用いた NP 推論; CoT および Faithful CoT ベースラインと複数データセットで比較。
- データセットには GSM8K, AQuA, MATH, AddSub, Date, Last Letters を含む。
実験結果
リサーチクエスチョン
- RQ1LLMs は Natural Program 形式で推論する際、各推論ステップの演繹的妥当性を検証できるか?
- RQ2逐次・前提最小化の検証は、エンドツーエンド検証と比較して厳密さと信頼性を向上させるか?
- RQ3演繹検証を UPV と統合すると、最終回答の正確さと堅牢性にどう影響するか?
- RQ4最小の前提と全前提を使用した場合の検証精度への影響は?
主な発見
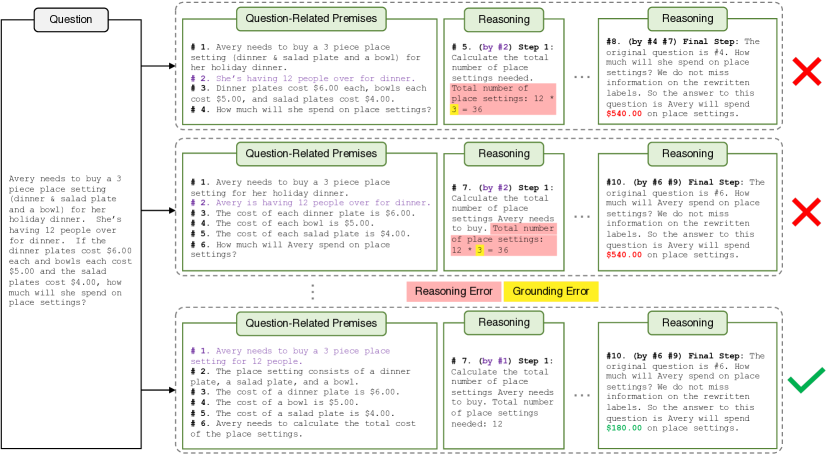
- Natural Program ベースの検証は、ほとんどのデータセットで逐次推論検証の精度を大幅に向上させる。
- ステップごとに最小限の前提を用いると、関連性の低い文脈による妨害を減らし、検証性能が著しく改善される。
- 単一ステップの有効性の投票数を増やすと(k')、検証精度が一般に向上するが、計算量が増える。
- Natural Program 形式でモデルにプロンプトを与えると、検証前でも多くのタスクで基準より同等またはそれ以上の最終回答精度を示す。
- 完全演繹検証を適用すると、正解を出すチェーンをフラグすることで最終回答精度がわずかに低下する場合があるが、推論の厳密さは向上する。
- アブレーションは、前提最小化と UPV の設定が検証精度と最終結果の両方に実質的な影響を与えることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。