[論文レビュー] Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
Deep Gradient Compressionは momentum correction、local gradient clipping、momentum factor masking、warm-up training を用いて勾配通信を270×から600×削減し、CNNとRNNで精度を保つ。
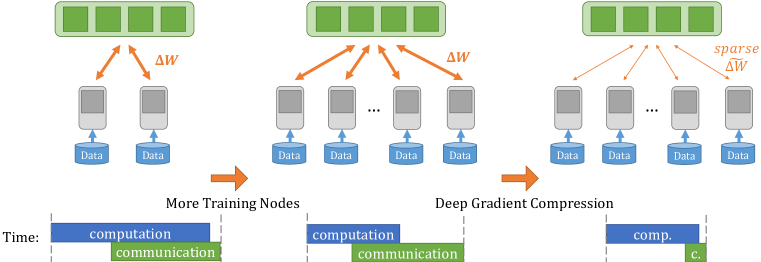
Large-scale distributed training requires significant communication bandwidth for gradient exchange that limits the scalability of multi-node training, and requires expensive high-bandwidth network infrastructure. The situation gets even worse with distributed training on mobile devices (federated learning), which suffers from higher latency, lower throughput, and intermittent poor connections. In this paper, we find 99.9% of the gradient exchange in distributed SGD is redundant, and propose Deep Gradient Compression (DGC) to greatly reduce the communication bandwidth. To preserve accuracy during compression, DGC employs four methods: momentum correction, local gradient clipping, momentum factor masking, and warm-up training. We have applied Deep Gradient Compression to image classification, speech recognition, and language modeling with multiple datasets including Cifar10, ImageNet, Penn Treebank, and Librispeech Corpus. On these scenarios, Deep Gradient Compression achieves a gradient compression ratio from 270x to 600x without losing accuracy, cutting the gradient size of ResNet-50 from 97MB to 0.35MB, and for DeepSpeech from 488MB to 0.74MB. Deep gradient compression enables large-scale distributed training on inexpensive commodity 1Gbps Ethernet and facilitates distributed training on mobile. Code is available at: https://github.com/synxlin/deep-gradient-compression.
研究の動機と目的
- 大規模トレーニングのための同期的分散 SGD における通信帯域幅の削減の必要性を動機づける。
- 高い疎性の下で精度を保つ勾配圧縮アプローチを提案する。
- 疎な更新によって生じる収束性と最新性の問題を緩和する仕組みを導入する。
提案手法
- 大きな勾配のみを送信し、小さな勾配は局所的に蓄積する勾配スパース化。
- スパースな勾配を 32-bit nonzeros と 16-bit zeros のラン長でエンコードする。
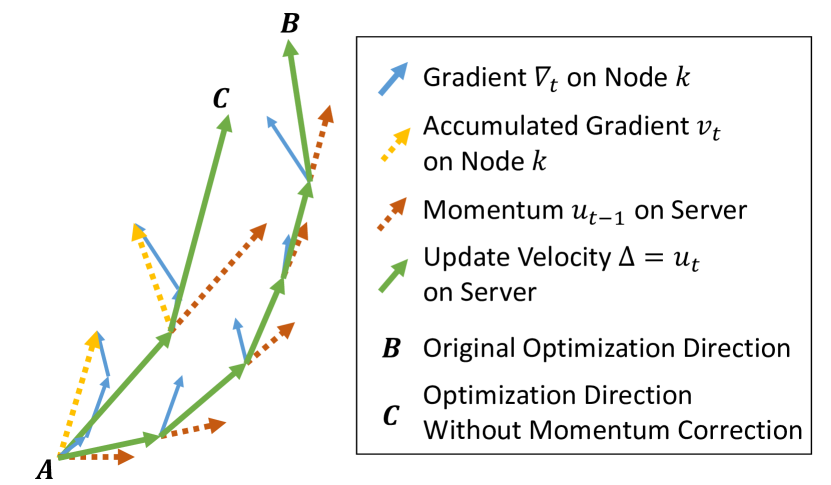
- 疎な更新を密集した momentum SGD の更新と整合させるための momentum correction。
- ノード内で爆発リスクを抑えるための局所的勾配クリッピング。
- 遅延勾配からの古い momentum の影響を減らすための momentum factor masking。
- 疎性によるトレーニング初期の不安定性を抑えるための warm-up training。
実験結果
リサーチクエスチョン
- RQ1勾配の交換を大幅に削減(数十倍レベルまで)しても精度を損なわないことは、さまざまなタスクで可能か。
- RQ2 momentum を伴う分散 SGD における疎性誘発の収束問題をいかに緩和できるか。
- RQ3CNNとRNNの両方で、帯域幅削減とモデル性能の間で最適なトレードオフを生む技術の組み合わせは何か。
- RQ4階層的しきい値設定など、スケーラブルな疎勾配選択を可能にするランタイム戦略は何か。
主な発見
- 勾配圧縮比は 270× から 600× の範囲で達成され、タスクとデータセットを跨いで精度の損失が見られない。
- ImageNet の ResNet-50 での圧縮は 277× に達し、基準と比較して精度の低下が微小(Top-1: 基準 58.17% vs DGC 58.20%、Top-5: 基準 80.19% vs DGC 80.20%)。
- CIFAR-10 上の ResNet-110 を 4 GPU で実行した場合、基準 Top-1 精度は 93.75%、DGC は 93.87%(+0.12%)。
- ImageNet を 4 GPU、総バッチサイズ 256 のとき、基準 Top-1 は 92.92%、DGC は 93.28%(+0.37%)。
- Penn Treebank の言語モデリングでは、基準のパープレキシティが 72.30、DGC が 72.24 で勾配サイズ 0.42 MB(462×圧縮)。
- LibriSpeech の自動音声認識では、テストクリーンでの WER が 基準 9.45% vs DGC 9.06%、勾配サイズ 0.74 MB(608×圧縮)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。