[論文レビュー] Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions
潜在空間で学習されたプロトタイプを介して予測を説明する、オートエンコーダとプロトタイプベースの層を組み合わせた解釈可能なニューラルネットワークを導入する。
Deep neural networks are widely used for classification. These deep models often suffer from a lack of interpretability -- they are particularly difficult to understand because of their non-linear nature. As a result, neural networks are often treated as "black box" models, and in the past, have been trained purely to optimize the accuracy of predictions. In this work, we create a novel network architecture for deep learning that naturally explains its own reasoning for each prediction. This architecture contains an autoencoder and a special prototype layer, where each unit of that layer stores a weight vector that resembles an encoded training input. The encoder of the autoencoder allows us to do comparisons within the latent space, while the decoder allows us to visualize the learned prototypes. The training objective has four terms: an accuracy term, a term that encourages every prototype to be similar to at least one encoded input, a term that encourages every encoded input to be close to at least one prototype, and a term that encourages faithful reconstruction by the autoencoder. The distances computed in the prototype layer are used as part of the classification process. Since the prototypes are learned during training, the learned network naturally comes with explanations for each prediction, and the explanations are loyal to what the network actually computes.
研究の動機と目的
- 深層学習における解釈可能な予測の必要性を動機づけ、標準的なニューラルネットワークにおける解釈性の欠如に対処する。
- ケースベースの説明を提供するために、オートエンコーダとプロトタイプ層を統合したニューラルアーキテクチャを提案する。
- 潜在空間のプロトタイプを入力空間へデコードして学習済みプロトタイプの可視化を可能にする。
- 専用の正則化項を通じて解釈性を高めつつ、モデルが競争力のある予測性能を維持することを保証する。
提案手法
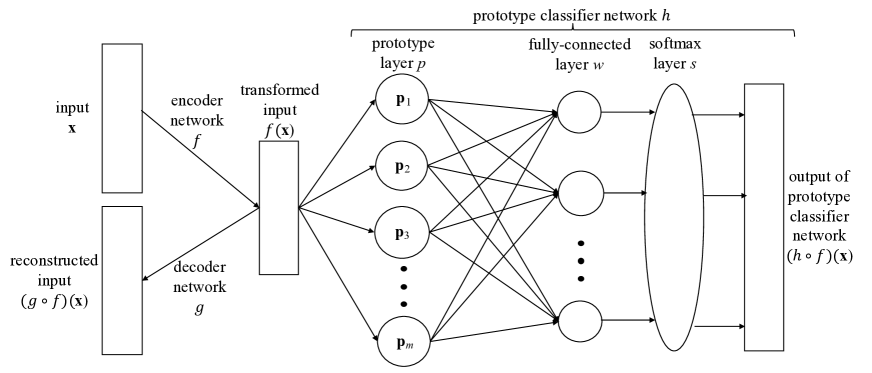
- 二成分アーキテクチャ: 潜在空間におけるオートエンコーダ(エンコーダ f とデコーダ g)とプロトタイプ分類ネットワーク h。
- Prototype layer p は、エンコードされた入力 z=f(x) と R^q 内のm個のプロトタイプ p1,...,pm との二乗L2距離を計算する。全結合層 W が距離をクラスロジットに結合し、続いてsoftmaxを適用する。
- 学習目的はクロスエントロピー損失 E、再構成損失 R、2つの解釈性正則化項 R1 および R2 を組み合わせ、超パラメータ付きの総損失 L = E(h∘f,D) + λR(g∘f,D) + λ1R1(...) + λ2R2(...)とする。
- R1 は各プロトタイプが潜在空間内の少なくとも1つのエンコード入力に近いことを奨励し、R2 はすべてのエンコード入力が少なくとも1つのプロトタイプに近いことを奨励する。
- プロトタイプベクトルは潜在空間に存在し、入力空間へデコードすることで可視化が可能になる; W はプロトタイプとクラス間の関係を反映するように学習させることができる。
実験結果
リサーチクエスチョン
- RQ1潜在空間内の学習済みプロトタイプを用いたケースベースの推論で予測を説明するようなニューラルネットワークを設計できるか。
- RQ2潜在空間のプロトタイプと明示的な正則化項を組み合わせると、精度を犠牲にせず意味のある可視化可能な説明が得られるか。
- RQ3解釈性項であるR1とR2がプロトタイプの質とデータセット間の一般化にどのように影響するか。
- RQ4プロトタイプからクラスへの重み行列 W を学習することが分類挙動と解釈可能性に与える影響は何か。
- RQ5このアーキテクチャは、非解釈可能なネットワークと比較して標準的な画像分類ベンチマークでどのように性能を発揮するか。
主な発見
- このモデルは MNIST (train 99.53%, test 99.22%), Fashion-MNIST (89.95%), および Cars データセットで競争力のある精度を達成しつつ、プロトタイプによる内在的な説明を提供する。
- デコードされたプロトタイプは現実的な数字や衣類アイテムに視覚的に似ており、R1とR2によって有効化された意味のある潜在空間表現を示している。
- アブレーション研究は、プロトタイプ層またはデコーダを削除すると非解釈可能なベースラインと同等の精度になることを示しており、解釈性がこれらのタスクで性能を大幅に低下させないことを示している。
- 学習された重み行列 W はどのプロトタイプが各クラスに最も影響を与えるかを明らかにし、クラス間の関係とプロトタイプの有用性への洞察を提供する。
- プロトタイプの可視化はクラス内のばらつき(例: 6と3の異なる筆跡スタイル)とクラス横の曖昧さを示し、ケースベース推論と整合している。
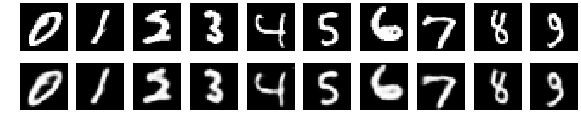
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。