[論文レビュー] Deep reinforcement learning from human preferences
この論文は、人間の軌跡セグメントの好みから報酬モデルを学習し、RLで最適化することで、真の報酬にアクセスできなくても複雑なタスクを可能にします。最小限の人間のフィードバックでAtariとMuJoCoのタスクを示します。
For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent's interactions with the environment. This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of our approach, we show that we can successfully train complex novel behaviors with about an hour of human time. These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.
研究の動機と目的
- 難しく指定する報酬を持つドメインで強化学習を動機づける。
- 絶対報酬ではなく人間の好みから学ぶための拡張可能な方法を開発する。
- 非専門家の人間のフィードバックの少量で大規模なタスクの深層RLを導けることを示す。
- AtariとMuJoCoで手作り報酬が難しい学習行動を示す。
提案手法
- 深層ネットを用いてパラメータ化された方針 π と報酬予測子 ĥr の両方を維持する。
- 軌跡セグメントを収集し、人間にセグメントのペアを比較させる。
- Bradley–Terry型モデルを用いて人間の好みに対するクロスエントロピー損失を最大化することで ĥr を適合させる。
- 予測報酬 ĥr を報酬信号として用いて RL で方針を訓練する。
- 学習を安定させるために報酬予測子のアンサンブルを使用し、その出力を平均化する。
- クエリはセグメントペアをサンプリングしてアンサンブルの不一致が高いものを選択して選ぶ。
実験結果
リサーチクエスチョン
- RQ1 native 報酬関数を持たずに、短い軌跡クリップにおける人間の好みは深層RLエージェントを十分な信号で訓練できるか?
- RQ2複雑なタスクで近似RL性能を達成するには、どれだけの人間のフィードバック(実データか合成/オラクルか)とどのタイプが必要か?
- RQ3オンラインの人間フィードバックは報酬の誤指定とエージェントによる悪用を防ぐか?
- RQ4このアプローチは複雑なドメイン(Atari, MuJoCo)にスケールし、報酬で手作業で作成しづらい新しい行動を生み出せるか?
主な発見
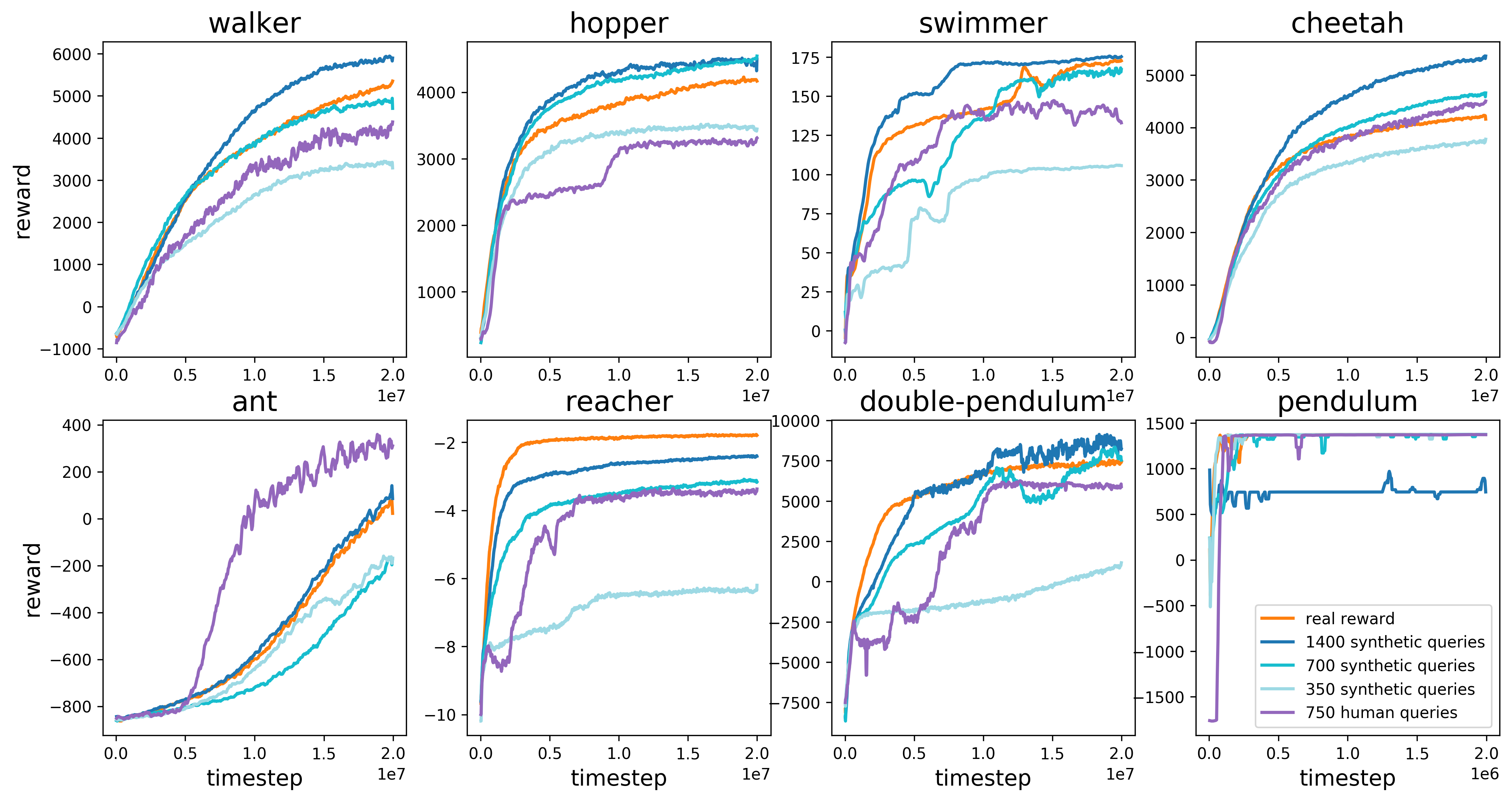
- この手法は、完全なデモンストレーションや報酬設計よりはるかに少ない人間作業時間で、AtariとMuJoCoの複雑なRLタスクを解くことを可能にする。
- 数百から千の人間の比較で、この方法は複数の MuJoCo タスクといくつかの Atari ゲームでほぼRLの性能に達する。
- 実際の人間のフィードバックは、タスクとラベリングの一貫性によってはsyntheticフィードバックと同程度またはやや劣ることが多い。
- この方法は人間の時間が1時間未満で新しい行動を学習できる(例:バックフリップ、交通量のある道を走行する運転など)。
- オンライン更新なしの offline 報酬予測子訓練は失敗する可能性があり、オンラインRLと人間のフィードバックを統合する重要性を示す。
- ĥr のアンサンブルの使用と軌跡クリップの比較は、学習の安定性と人間の判断との整合性を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。