[論文レビュー] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Deep Speech 2 は、English と Mandarin ASR のエンドツーエンド深層学習を実証し、大規模データとHPC加速トレーニングにより競争力のある精度を達成し、低遅延でオンライン展開可能である。
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.
研究の動機と目的
- 最小限の言語特有のエンジニアリングで English および Mandarin にまたがって動作するエンドツーエンドの ASR を実証する。
- 精度向上のための深いアーキテクチャ(畳み込み層および再帰層)とトレーニング手法を調査する。
- 迅速な実験とモデル展開を可能にするため、large-scale labeled data と HPC 最適化を活用する。
- 標準ベンチマークおよび人間による転写と比較して性能を評価し、実運用展開の考慮事項を検討する。
提案手法
- スペクトログラム入力を grapheme 出力へマップするエンドツーエンド RNN-CTC フレームワークを使用する。
- 深い RNN に対して batch normalization を含む、複数の畳み込み層と双方向再帰層を含むアーキテクチャを探る。
- 可変長の発話での訓練を安定化させるため、カリキュラムベースの SortaGrad 訓練戦略を適用する。
- GRU と単純な RNN セルを比較して精度と訓練効率のトレードオフを検討する。
- 周波数-時間の畳み込みとストライドを組み込んで time-steps と計算量を削減する。
- 低遅延オンラインデコーディングと BatchNorm 対応の展開戦略のために一方向 row-convolution を導入する。

実験結果
リサーチクエスチョン
- RQ1CTC で訓練されたエンドツーエンド深層ネットワークは、手作業で設計された成分を用いずに English および Mandarin で競争力のある WER/CER を達成できるか?
- RQ2ネットワークの深さ、畳み込み戦略、再帰ユニットの種類は、English および Mandarin における認識精度にどのように影響するか?
- RQ3このようなモデルを現実的な時間枠で訓練するために、どの程度のデータ規模とHPC最適化が必要か?
- RQ4大規模で低遅延のオンライン認識を実現するための展開戦略(batch dispatch、unidirectional models)は何か?
主な発見
- 複数のベンチマークで prior end-to-end systems より English WER を最大 43% 減少させた。
- English の訓練データ 11,940 hours と Mandarin データ 9,400 hours を用いて大規模・深いモデルを訓練。
- 訓練は 16 GPUs で約 50 teraFLOP/s を維持し、3–5 日の実験と迅速な反復を可能にする。
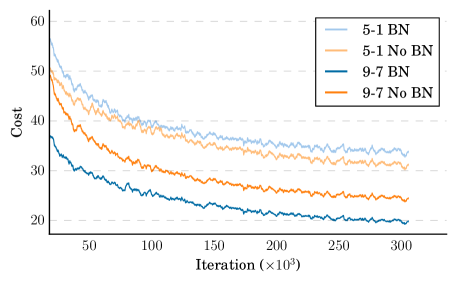
- シーケンスごとの統計量を用いたBatch normalization は訓練を加速させ、深い RNN の一般化を改善する。
- GRU セルは同等パラメータ数で単純な RNN より性能が上回るが、非常に大規模なモデルでは固定計算予算下で simple RNN も競争力を持ち得る。
- Mandarin 展開は BatchNorm と row-convolution を用いた低遅延を達成(98th percentile compute latency 67 ms, 10 simultaneous streams)。
- English および Mandarin のための効果的にラベル付きデータをさらに拡張するためのデータ拡張と合成の活用。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。