[論文レビュー] DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeek-Coder-V2 はオープンソースの Mixture-of-Experts コードモデル(16B および 236B)で、コードと数学タスクの性能で閉源モデルに近づくか上回り、338言語へ言語サポートを拡張し、コンテキスト長を128Kトークンへ増やします。
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K. In standard benchmark evaluations, DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.
研究の動機と目的
- オープンソースのコードモデルと閉源リーダー(例:GPT-4-Turbo)とのギャップを、コーディングと数学タスクの領域で埋める。
- 多様なプログラミング言語と長距離コード理解をサポートするために言語とコンテキストのカバレッジを拡大する。
- 長期コンテキスト訓練と多源的事前学習、RLベースのアラインメントを通じてコーディングと数学的推論を向上させる。
- 研究と商用利用の制限を緩和したオープンソースモデルを許容ライセンスの下で公開する。
提案手法
- DeepSeek-V2 の中間チェックポイントから追加の6兆トークンを用いた継続的事前学習、コード・数学・自然言語領域を合わせて総計10.2兆トークン訓練。
- コードコーパスを86言語から338言語へ拡張し、コードトークンを1,170Bに増加、混合比は60%コード・10%数学・30%自然言語。
- Yarnフレームワークを用いて16Kから128Kトークンへ拡張した長期コンテキスト訓練を段階的に実施。
- 2段階のアラインメント:コード・数学・一般データを組み合わせた命令データセットでの教師ありファインチューニング、その後、報酬モデルをコンパイラ/テストケースのフィードバックで調整したグループ相対政策最適化(GRPO)を用いた強化学習。
- 16B ではコード補完を強化するために Fill-In-Middle(FIM)訓練(Prefix-Suffix-Middle 構造)を採用; 236B では Next-Token-Prediction 目的に依拠。
- コーディング・数学・NLタスク全般でオープン-およびクローズドソースのベースラインと比較して性能向上を検証。
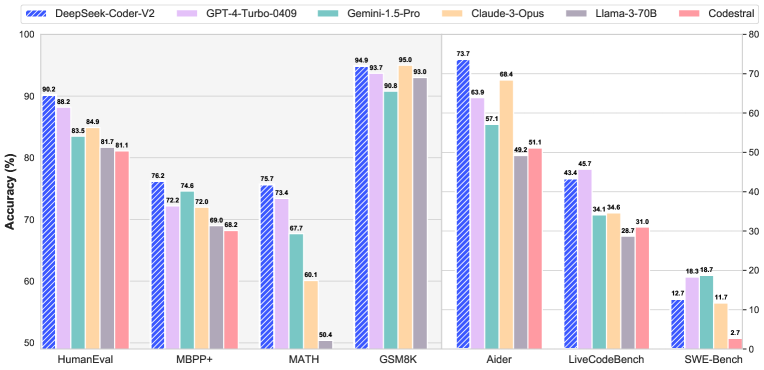
実験結果
リサーチクエスチョン
- RQ1オープンソースの Mixture-of-Experts コードモデルは、コーディングと数学のベンチマークで閉源リーダーと同等、あるいはそれを上回ることができるか。
- RQ2プログラミング言語カバレッジとコンテキスト長の拡大は、コーディングの正確さと推論能力にどのように影響するか。
- RQ3データ構成・長期コンテキスト訓練・RLアラインメント戦略がオープンソースのコードモデルの性能に与える影響は何か。
- RQ4オープンソースモデルがコードと数学タスクに特化しつつ、一般言語機能をどの程度維持できるか。
主な発見
- DeepSeek-Coder-V2(236B)は、コードと数学のベンチマークでGPT-4-Turbo、Claude 3 Opus、Gemini 1.5 Proと同等以上の性能を達成。
- コードベンチマークでは236Bモデル(EvalPlusパイプライン)で HumanEval 90.2%、MBPP 76.2%、LiveCodeBench 43.4% を示す。
- 数学タスクでは DeepSeek-Coder-V2 が MATH で 75.7% に達し、GPT-4o にほぼ匹敵し、AIME 2024 などの閉源モデルを上回る。
- 本モデルは338言語をサポートし、前作の86言語・16Kコンテキストから最大128Kトークンへ拡張。
- オープンソースの DeepSeek-Coder-V2-Instruct は、言語を組み合わせた HumanEval/MBPP の平均75.3%を達成し、 benchmark セットで GPT-4o に次ぐ位置。
- 長期コンテキストとFIM対応の変種(16B)は、コード補完と修復能力が高く、FIMタスクと修復ベンチマークで顕著な結果を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。