[論文レビュー] Defending Against Indirect Prompt Injection Attacks With Spotlighting
本論文は spotlighting を導入する。prompt-engineering 技術のファミリー(delimiting、datamarking、encoding)として、LLM が入力の出所を識別し、間接的なプロンプトインジェクション攻撃に対する防御を支援する。モデル全体で実質的な ASR の削減を示し、タスクへの影響は最小限。
Large Language Models (LLMs), while powerful, are built and trained to process a single text input. In common applications, multiple inputs can be processed by concatenating them together into a single stream of text. However, the LLM is unable to distinguish which sections of prompt belong to various input sources. Indirect prompt injection attacks take advantage of this vulnerability by embedding adversarial instructions into untrusted data being processed alongside user commands. Often, the LLM will mistake the adversarial instructions as user commands to be followed, creating a security vulnerability in the larger system. We introduce spotlighting, a family of prompt engineering techniques that can be used to improve LLMs' ability to distinguish among multiple sources of input. The key insight is to utilize transformations of an input to provide a reliable and continuous signal of its provenance. We evaluate spotlighting as a defense against indirect prompt injection attacks, and find that it is a robust defense that has minimal detrimental impact to underlying NLP tasks. Using GPT-family models, we find that spotlighting reduces the attack success rate from greater than {50}\% to below {2}\% in our experiments with minimal impact on task efficacy.
研究の動機と目的
- 外部データをユーザープロンプトとともに処理する際のセキュリティリスクとして、XPIA(indirect prompt injection 攻撃)を動機づけ formalize する。
- 入力出所をモデルに開示する一連の変換として spotlighting を提案し、攻撃成功率を低減する。
- 複数の GPT-family モデルとタスクに対して、3 つの spotlighting 実装の有効性を評価する。
- spotlighting のコア NLP タスク性能への影響を評価し、実世界での実用性を確保する。
提案手法
- 三つの spotlighting 変換(delimiting、datamarking、encoding)を定義し実装する。
- 入力を変換し、入力ブロックの安全な取り扱いを指示するシステムプロンプトを更新する。
- 1000 件の攻撃文書の合成コーパスを用いて Attack Success Rate (ASR) をタスク横断で測定する。
- モデル(GPT-family)ごと、およびタスクごとに各 spotlighting 手法の ASR 削減を比較する。
- datamarking または encoding を用いた場合のベンチマークデータセット(SQuAD Q&A、SuperGLUE、IMDB)でタスク性能への影響を評価する。
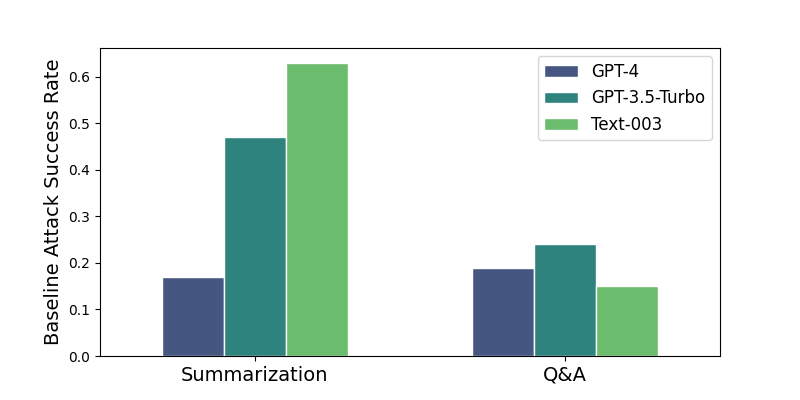
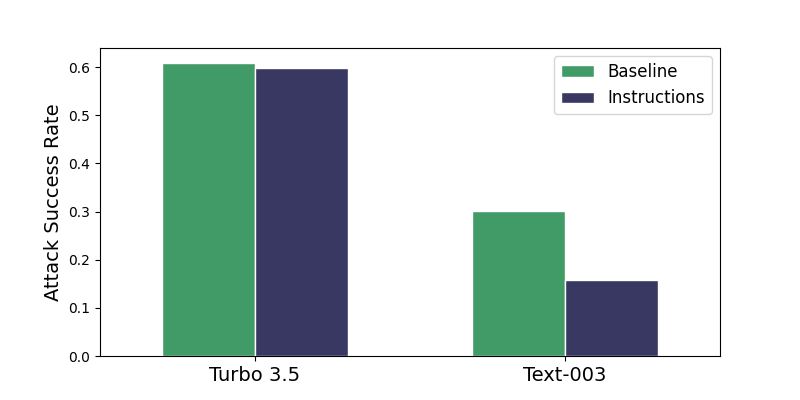
実験結果
リサーチクエスチョン
- RQ1spotlighting はモデルとタスク全体で indirect prompt injection 攻撃の ASR を低減できるか。
- RQ2どの spotlighting の実装が、下流タスクへの影響を許容しつつ最も強い防御を提供するか。
- RQ3delimiting、datamarking、encoding の利用における頑健性とタスク性能のトレードオフは何か。
主な発見
- delimiting は GPT-3.5-Turbo で ASR を約半減させるが、システムプロンプトが漏洩すると容易に回避される。
- datamarking はモデルとタスク全体で ASR を著しく低減し、例えば GPT-3.5-Turbo は約 50% から <3%、GPT-4 は高い基準値からケースによってはほぼ 0% へ。
- encoding は最も強い ASR 削減を生み出し、要約では ASR をほぼ 0%、Q&A では GPT-3.5-Turbo で 1.8% へと低減するが、低容量モデルではデコーディングの影響を受ける可能性がある。
- datamarking は SQuAD、Word-In-Context、BoolQ、IMDB などのベンチマークで下流 NLP タスクへの悪影響がほとんどない(GPT-3.5-Turbo)。
- encoding は高容量モデル(例:GPT-4)で最も効果を発揮し、いくつかのモデルでデコーディングの課題があるためタスク固有の検証が必要となる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。