[論文レビュー] DeltaGrad: Rapid retraining of machine learning models
DeltaGrad は、トレーニングサンプルの小さな集合が追加または削除されたときに、トレーニング情報をキャッシュし、L-BFGS による近似ハessian を用いてモデルを効率的に更新することで、モデルの高速な再訓練方法を提供します。
Machine learning models are not static and may need to be retrained on slightly changed datasets, for instance, with the addition or deletion of a set of data points. This has many applications, including privacy, robustness, bias reduction, and uncertainty quantifcation. However, it is expensive to retrain models from scratch. To address this problem, we propose the DeltaGrad algorithm for rapid retraining machine learning models based on information cached during the training phase. We provide both theoretical and empirical support for the effectiveness of DeltaGrad, and show that it compares favorably to the state of the art.
研究の動機と目的
- datasets が変わったときに迅速なモデル再訓練の必要性を動機づけること(例:プライバシー、堅牢性、バイアス補正、不確実性の定量化)。
- SGD/GD によって解かれる経験的リスク最小化に対して追加の乱択化なしで適用可能な一般的な再訓練手法を開発すること。
- incremental updates の精度に関する理論的保証を提供し、標準データセット上で経験的な速度向上を示すこと。
提案手法
- DeltaGrad を導入し、小さなデータの変更後に leave-r-out 勾配設計を用いてモデルのパラメータを更新すること。
- フルデータ訓練からの勾配とパラメータベクトルをキャッシュして、increment に対して準ニュートンステップ(L-BFGS)で新しい勾配を近似すること。
- 正確な勾配を定期的に計算(Burn-in と毎の T0 回の反復)し、歴史的な変分を用いて近似ハessian B_t を形成すること。
- Cauchy 平均値定理を用いて更新点での勾配と元の点での勾配を関連づけ、効率的な近似を可能にすること。
- 確率的勾配降下法(SGD)へ拡張し、ミニバッチでの収束保証を標準的な仮定(強凸性、滑らかさ、勾配の有界性、リプシッツ連結 Hessian)下で提供すること。
- DeltaGrad がスクラッチからの再訓練より高速になるタイミングを示す複雑さ解析を提供し、特に n に対して小さな r の場合の利点を示すこと。
実験結果
リサーチクエスチョン
- RQ1DeltaGrad は、小さな数のトレーニングサンプルが追加または削除されたときにモデルを効率的に更新できるか。
- RQ2更新後のデータセットで再訓練する場合と比較したときの DeltaGrad の精度に関する理論的保証は何か。
- RQ3標準データセットとモデルタイプ(ロジスティック回帰、ニューラルネットワーク)において、速度と精度の観点で DeltaGrad は実際にどう機能するか。
- RQ4DeltaGrad を SGD およびミニバッチ設定へ拡張するにはどうすればよく、関連する収束特性は何か。
- RQ5迅速な再訓練から生じる実用的な適用(プライバシー、堅牢性、デバイアス是正、不確実性の定量化)は何か。
主な発見
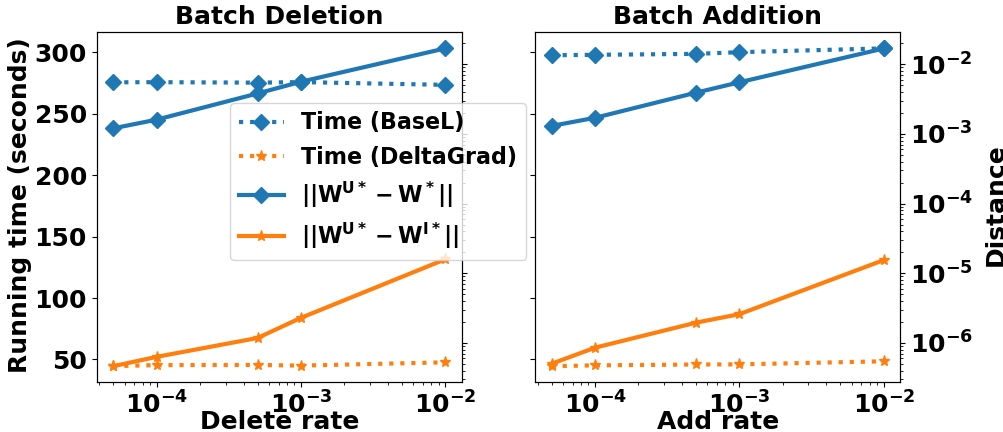
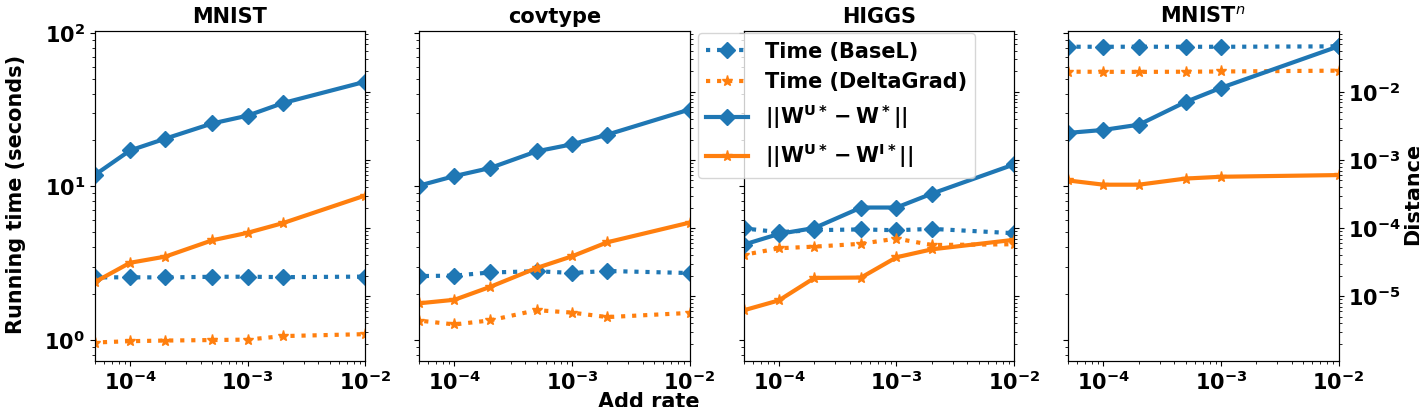
- DeltaGrad は、データの小さな割合が追加または削除された場合に、実験で最大 6.5x の大幅な速度向上を達成し、精度低下は極めて小さい。
- DeltaGrad によって得られる増分更新は、真の再訓練済みパラメータを密接に追跡し、正解解との差(w^U* − w^*)の通常は基準偏差よりも1桁小さくなる。
- DeltaGrad は複数のデータセット(MNIST、covtype、HIGGS、RCV1)で有効であり、単純なニューラルネットワークや二層ネットワークにも適応する。
- 理論的結果は、強凸目的関数に対して誤差 ||w^U_t − w^I_t|| が o(r/n) であることを示し、データ変更の割合が小さくなると近似が正確になることを示唆する。
- SGD 設定では、DeltaGrad はミニバッチサイズ B の増加とともに誤差境界が縮むことを示し、B が大きく r/n が小さい場合に近似が正確であることを示す。
- 実験結果には、バッチとオンラインの追加/削除の両方が含まれ、堅牢な速度向上と一貫した予測性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。