[論文レビュー] Denoising Diffusion Semantic Segmentation with Mask Prior Modeling
要約: 本論文は DDPS を提案する。離散拡散ベースのマスク事前情報を用いて基礎セグメンテーション予測を改良し、ADE20KとCityscapesでIoUと境界精度を向上させる二段階フレームワーク。
The evolution of semantic segmentation has long been dominated by learning more discriminative image representations for classifying each pixel. Despite the prominent advancements, the priors of segmentation masks themselves, e.g., geometric and semantic constraints, are still under-explored. In this paper, we propose to ameliorate the semantic segmentation quality of existing discriminative approaches with a mask prior modeled by a recently-developed denoising diffusion generative model. Beginning with a unified architecture that adapts diffusion models for mask prior modeling, we focus this work on a specific instantiation with discrete diffusion and identify a variety of key design choices for its successful application. Our exploratory analysis revealed several important findings, including: (1) a simple integration of diffusion models into semantic segmentation is not sufficient, and a poorly-designed diffusion process might lead to degradation in segmentation performance; (2) during the training, the object to which noise is added is more important than the type of noise; (3) during the inference, the strict diffusion denoising scheme may not be essential and can be relaxed to a simpler scheme that even works better. We evaluate the proposed prior modeling with several off-the-shelf segmentors, and our experimental results on ADE20K and Cityscapes demonstrate that our approach could achieve competitively quantitative performance and more appealing visual quality.
研究の動機と目的
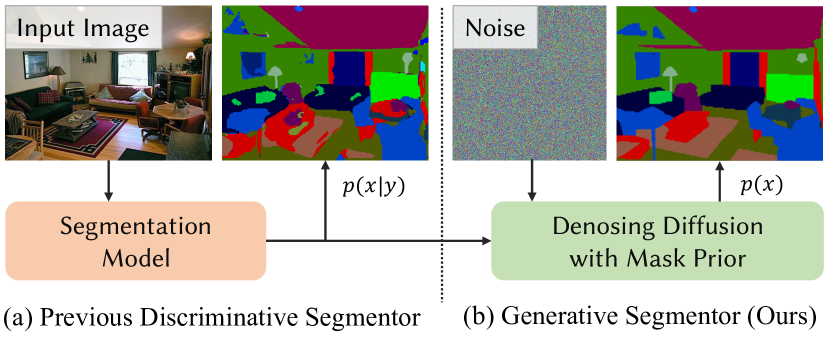
- 判別型セグメンテーションとセグメンテーションマスク priors のギャップを、マスクの p(x) を denoising diffusion でモデル化することで埋める。
- マスク表現のコーデック、基礎セグメンテータ、予測を refine する拡散 prior を備えた統一的な DDPS アーキテクチャを提案する。
- セグメンテーションにおける離散拡散の設計選択を検討し、訓練/推論戦略を評価する。
- 拡散 priors の組み込みが標準ベンチマークで定量的な利益と視覚的品質の改善をもたらすことを示す。
提案手法
- 二段階パイプラインを使用する:初期予測を生成する固定された基礎セグメンテーションモデルと、マスク priors を反復的に refine する拡散ベースの prior。
- マスク表現コーデック上で動作する離散拡散過程を採用(例:離散拡散を伴う単純リサイズコーデック)。
- 清潔なマスク x0 を予測する x0-パラメータ化デノイザー(UNet)を用い、拡散中に x(t-1) を導く。Training は Noise-on-First-Prediction の戦略。
- 二段階訓練:まず最大ノイズでの単一ステップ拡散を行い、次に複数ステップの拡散でファインチューニング。
- 置換のみの拡散遷移(均一置換)と Noise-on-First-Prediction のターゲットを用い、訓練と推論を一致させる。
- 推論時に基礎セグメンターからの条件付けを高めるために CFG(Classifier-Free Guidance)を適用する。
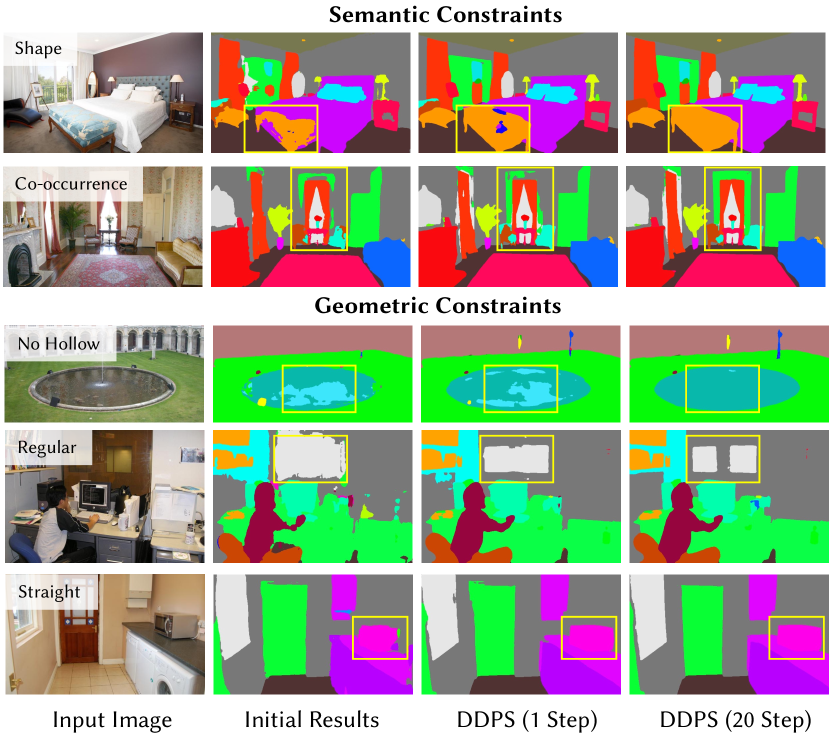
実験結果
リサーチクエスチョン
- RQ1拡散ベースのマスク priors モデリングは、既存の識別型セグメンテーションの成果を向上させるか。
- RQ2セグメンテーションにおける効果的な離散拡散を可能にする主要な設計選択(遷移タイプ、拡散ターゲット、訓練/推論戦略)は何か。
- RQ3DDPS は標準ベンチマーク(ADE20K、Cityscapes)で mIoU と境界 IoU に対してベースラインと比較してどのような影響を与えるか。
- RQ4厳密な拡散過程の推論戦略は必須か、それとも再ノイズ化のより単純な戦略で十分か。
- RQ5反復 refining とストライドサンプリングが性能と効率に与える影響はどうか。
主な発見
- DDPS は CNN- およびトランスフォーマーベースのモデルの基礎セグメンテーション予測を一貫して refine する。
- ADE20K では Segformer-SF と MiT-B2/B0 を用いた DDPS が顕著な mIoU 増加と境界 IoU の改善を示し、様々な構成でおおよそ 3-5 ポイント程度の増加が報告される。
- Cityscapes では DDPS がいくつかのベースラインを改善し、より強力なバックボーンと高容量デコーダと組み合わせた場合に顕著な利益が得られる。
- 拡散遷移タイプの影響は控えめ、拡散ターゲットは重要(ノイズ on GT はより大きな低下を引き起こす)、推論時の自由再ノイズ化戦略は厳密な後方デノイジングより優れる場合がある。
- 第一予測駆動ノイズと多段階訓練は第一歩の性能に有意な利益をもたらし、反復 refining は追加の利益を提供する(例:20ステップ後)。
- CFG は推論時に基礎セグメンターからの条件情報を活用することで性能をさらに向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。