[論文レビュー] Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
tldr: DEPS はオープンワールドのマルチタスクエージェントのための LLM を用いた対話型計画フレームワークで、describe、explain、plan、select の循環と horizon-predictive selector によって計画の信頼性を向上させる。ゼロショットの Minecraft 性能が高く、ALFWorld およびテーブルトップのタスクにも一般化する。
We investigate the challenge of task planning for multi-task embodied agents in open-world environments. Two main difficulties are identified: 1) executing plans in an open-world environment (e.g., Minecraft) necessitates accurate and multi-step reasoning due to the long-term nature of tasks, and 2) as vanilla planners do not consider how easy the current agent can achieve a given sub-task when ordering parallel sub-goals within a complicated plan, the resulting plan could be inefficient or even infeasible. To this end, we propose "$\underline{D}$escribe, $\underline{E}$xplain, $\underline{P}$lan and $\underline{S}$elect" ($ extbf{DEPS}$), an interactive planning approach based on Large Language Models (LLMs). DEPS facilitates better error correction on initial LLM-generated $ extit{plan}$ by integrating $ extit{description}$ of the plan execution process and providing self-$ extit{explanation}$ of feedback when encountering failures during the extended planning phases. Furthermore, it includes a goal $ extit{selector}$, which is a trainable module that ranks parallel candidate sub-goals based on the estimated steps of completion, consequently refining the initial plan. Our experiments mark the milestone of the first zero-shot multi-task agent that can robustly accomplish 70+ Minecraft tasks and nearly double the overall performances. Further testing reveals our method's general effectiveness in popularly adopted non-open-ended domains as well (i.e., ALFWorld and tabletop manipulation). The ablation and exploratory studies detail how our design beats the counterparts and provide a promising update on the $ exttt{ObtainDiamond}$ grand challenge with our approach. The code is released at https://github.com/CraftJarvis/MC-Planner.
研究の動機と目的
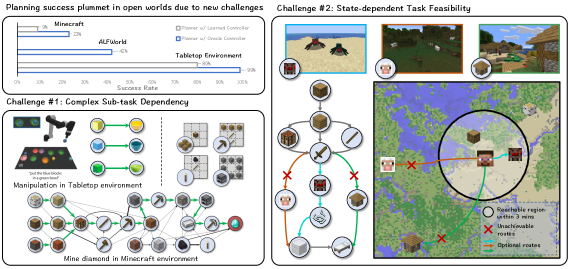
- オープンワールド(例: Minecraft)における長期的な計画の課題に対処し、計画が実現不能または非効率になる可能性を減らす。
- descriptor および explainer のフィードバックを通じてエラー対応型の計画修正を可能にし、計画の頑健性を向上させる。
- 学習可能な horizon ベースのゴールセレクタを導入して、近期かつ到達可能なサブゴールを選択することにより計画の実現性を高める。
- 環境特異の計画トレーニングを必要とせず、70+ の Minecraft タスクをゼロショットで解決する能力を示す。
- ALFWorld やテーブルトップ操作のようなオープンエンドでないドメインへの一般化を示す。
提案手法
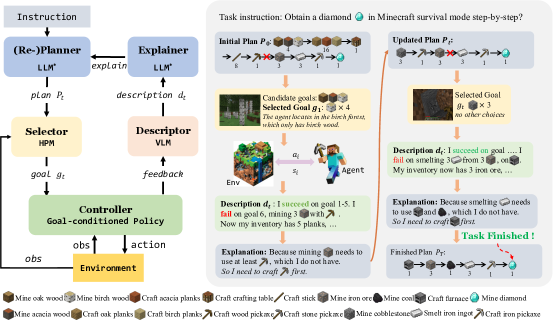
- DEPS を提案する:LLM が descriptor、explainer、planner の役割を果たし、サブゴールを反復的に洗練させるループ。
- サブゴールの実行失敗後の現在の状態を要約する descriptor を用い、それを LLM に自己説明と再計画のために-feed する。
- 各候補サブゴールを完了するまでの残り手順数(horizon)を推定し、最近傍/最も実現可能なものを選択する horizon-predictive selector を導入する。
- ゴール実現性と horizon を予測する selector backbone(Impala CNN ベース)を訓練し、計画の効率を向上させる。
- ゼロショットの LLM プランナーと、学習したポリシーを介してサブゴールを実行するゴール条件付きコントローラを用いてアプローチを実証する。
実験結果
リサーチクエスチョン
- RQ1オープンワールドの長期タスクにおける失敗から、LLM ベースのプランナーはどのように回復できるか?
- RQ2フィードバック駆動の再計画(describe, explain, plan)は、オープンワールドでのワンショット計画より成功率を改善できるか?
- RQ3horizon-aware セレクタはオープンワールドのサブゴール列の効率性と実現性を改善するか?
- RQ4DEPS は Minecraft を超えて ALFWorld やテーブルトップ操作のような他のドメインへどの程度一般化するか?
- RQ5オープンエンド環境における複数回の再計画ラウンドがタスク成功に与える影響は?
主な発見
| 方法 | MT1 | MT2 | MT3 | MT4 | MT5 | MT6 | MT7 | MT8 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| DEPS | 79.77 | 79.46 | 62.40 | 53.32 | 29.24 | 13.80 | 12.56 | 0.59 | 48.56 |
- DEPS は 71 の Minecraft タスクで全ての言語プランナーのベースラインを大幅に上回り、全体成功率をほぼ倍増させる。
- アブレーション解析は、Description、Self-explanation、Re-planning(DEP)を含む DEPS が従来のプランナーを上回り、セレクタを追加した DEPS はさらに改善をもたらす。
- horizon-predictive セレクタは特に多くの並行ゴールがあるタスクで効率を改善し、実現性のランキングでビジョン言語ベースラインを上回る。
- 再計画ラウンドを増やすと成功率が上昇し、難易度が高いタスクほど効果が大きくなり、horizon 制約のトークン制限まで進む。
- DEPS は ObtainDiamond で 0.59% を 10 分以内に達成し、タスク固有の微調整なしで現代的なゼロショット計画性能に匹敵し、クロスドメインの結果(ALFWorld、Tabletop)も示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。