[論文レビュー] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
SparKは階層的UNet風デコーダを用いた疎なマスキングを導入し、畳み込みネットワーク上でBERT風マスク化学習を可能にし、バックボーン変更なしでImageNet、COCO検出、セグメンテーションにおいて強い利得を達成する。
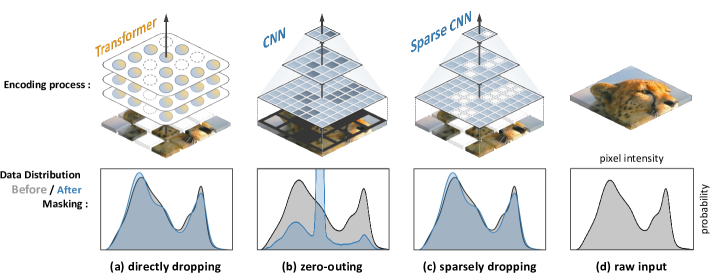
We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
研究の動機と目的
- Identify why BERT-style pre-training struggles for convnets and how to adapt masked modeling to irregular masked inputs.
- Develop a generative pre-training framework that works natively with convolutional backbones without modifications.
- Incorporate multi-scale hierarchical decoding to leverage convnets’ hierarchy for image reconstruction.
- Demonstrate transferability of learned features to downstream tasks like classification, object detection, and segmentation.
提案手法
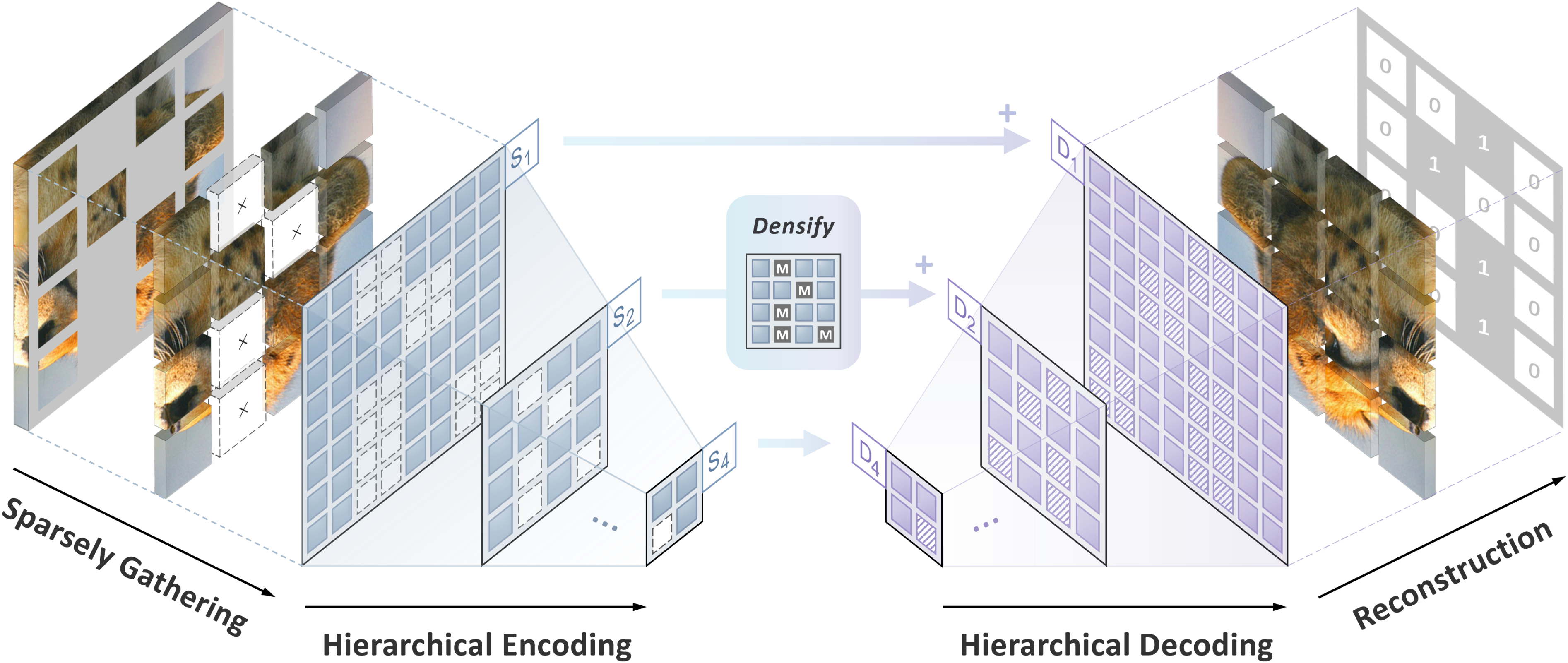
- Mask images patch-wise and gather unmasked patches into a sparse 3D-like representation for sparse convolution encoding.
- Use a UNet-inspired hierarchical decoder to reconstruct images from multi-scale encoded features by densifying sparse maps with mask embeddings.
- Optimize with an L2 reconstruction loss on masked patches, enabling end-to-end pre-training of the encoder while discarding the decoder at fine-tuning.
- Show that SparK can be applied to any convnet backbone (e.g., ResNet, ConvNeXt) without backbone modifications.
- Experiment with 1.28M ImageNet-1K unlabeled images, 1600 pretraining epochs, 60% mask ratio, 32 patch size, and LAMB optimizer.
実験結果
リサーチクエスチョン
- RQ1Can convnets be effectively pre-trained with BERT-style masked modeling without backbone changes?
- RQ2How can irregular masked inputs be handled in convnets without distribution shift or loss of masking effectiveness?
- RQ3Does hierarchical (multi-scale) decoding improve reconstruction and learned representations for convnets?
- RQ4Do convnet-based pre-trained features transfer to downstream tasks such as object detection and instance segmentation as well as or better than transformer-based methods?
主な発見
- SparK outperforms state-of-the-art contrastive and transformer-based masked modeling on ImageNet when using convnet backbones, with around +1.0% top-1 gains for ConvNeXt-S/B and larger gains for larger models.
- On COCO object detection and instance segmentation, SparK yields up to +3.5% AP improvements over baselines.
- SparK demonstrates favorable scaling, with larger models showing greater gains over non-pretrained counterparts.
- SparK achieves overall superiority among self-supervised methods while being the only generative pre-training approach for convnets in the reported comparisons.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。