[論文レビュー] Detecting Pretraining Data from Large Language Models
WikiMIAという動的ベンチマークを導入し、テキストがLLMの事前学習データの一部であったかどうかを検出する。参照なしのMin-k% Probという、外れ値トークンの確率を用いて所属を検出する手法を提案する。複数のモデルと実世界のシナリオで、ベースラインを上回る検出性能を示す。
Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to three real-world scenarios, copyrighted book detection, contaminated downstream example detection and privacy auditing of machine unlearning, and find it a consistently effective solution.
研究の動機と目的
- 大規模言語モデルの事前学習コーパスにおける潜在的な著作権保護対象、プライベート、またはベンチマークデータを特定する必要性を動機づける。
- 事前学習データ検出手法を評価するための動的でモデルに依存しないベンチマーク(WikiMIA)を作成する。
- シャドウモデルや事前学習分布へのアクセスを必要とせず、軽量で参照なしの検出法(Min-k% Prob)を提案する。
- WikiMIAとベースラインを用いてMin-k% Probを経験的に検証し、著作権、プライバシー監査、およびデータセット汚染シナリオへ適用する。
提案手法
- 事前学習データ検出問題を黒箱LMアクセスを前提とするMembership Inference Attackとして定義する。
- WikiMIAを構築するために、2023年前後のWikipediaイベントデータを用いてseen(member)とunseen(non-member)セットを作成する。
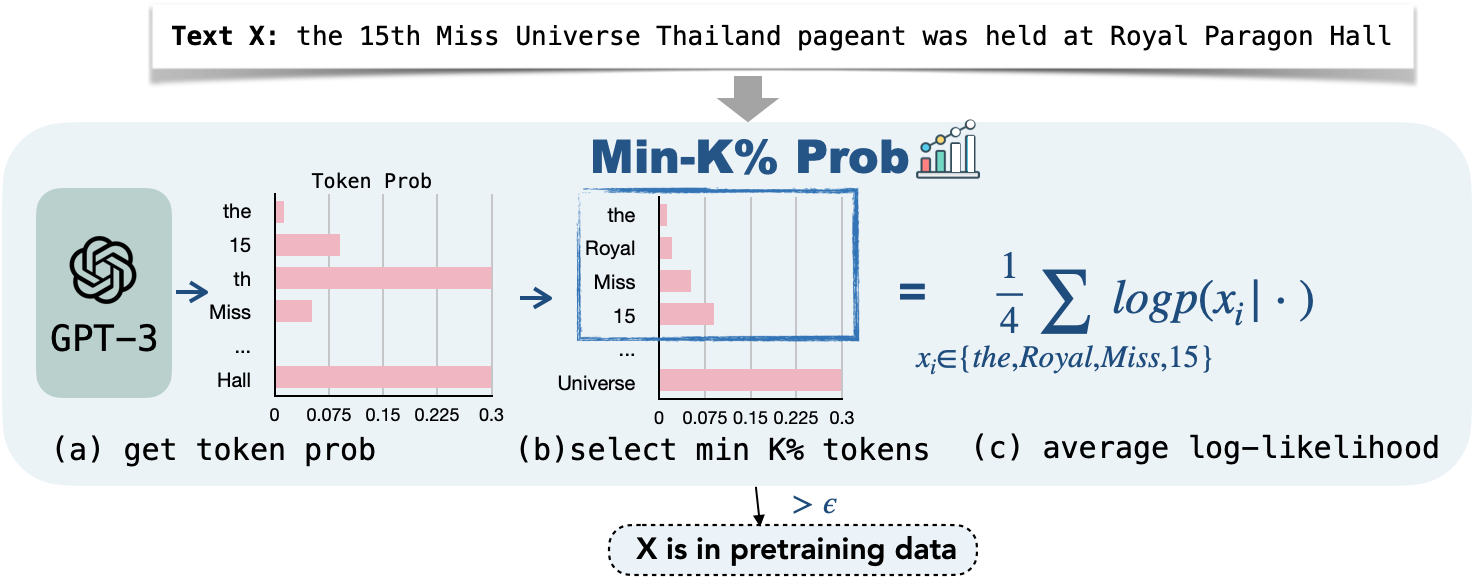
- Min-k% Probを提案する:テキスト上のトークン確率を計算し、最低のk%の確率を選択し、それらの対数尤度を平均して、参照モデルなしで所属を検出する。
- Min-k% Probを正当化する仮説として、 unseenデータにはseenデータよりもアウトライア低確率トークンが多く含まれる。
- Min-k% Probを、複数のモデルとテキスト長にわたり、ベースライン(LOSS/PPL、Zlib、Lowercase、Smaller Ref、Neighbor)と比較して評価する。
- 検出に影響を与える要因を調べる:モデルサイズとテキスト長。
- Min-k% Probを実世界タスクへ適用する:著作権で保護された書籍の検出、機械的忘却のプライバシー監査、下流データセット汚染。
実験結果
リサーチクエスチョン
- RQ1LMへの黒箱アクセスだけで、テキストがモデルの事前学習データの一部であると信頼性高く検出できるか。
- RQ2単純な参照なし検出器(Min-k% Prob)は、シャドウモデルや較正された確率に依存するベースラインよりも優れているか。
- RQ3モデルサイズ、テキスト長、言い換え(パラフレーズ)が事前学習データ検出性能にどう影響するか。
- RQ4著作権検出、プライバシー監査、データセット汚染のような実世界のシナリオで手法は有効か。
主な発見
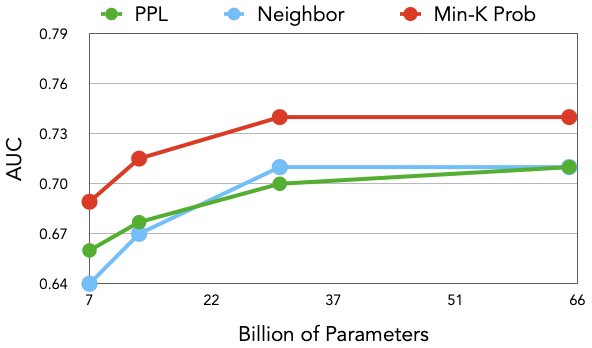
- Min-k% Probは、複数モデルでベースラインより高いAUCを達成(平均AUC 0.72、最良ベースラインを7.4%上回る)。
- 検出性能はモデルサイズの大きさとテキスト長の長さとともに向上する。
- パラフレーズ設定でもMin-k% Probは高い検出性能を示し、ベースラインを上回る。
- 著作権対象の書籍検出では、Min-k% ProbはAUC0.88を達成し、Books3の断片に大きな汚染を明らかにした。
- 汚染された下流データ検出は、汚染物がアウトライヤーであり、学習率が高い場合にAUCが高くなると、著者の理論的主張を裏付ける。
- プライバシー監査のケースでは、機械的忘却後の残留コンテンツを検出できることを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。