[論文レビュー] DETRs with Collaborative Hybrid Assignments Training
本論文は Co-DETR を導入します。複数の補助ヘッドを DETR ライク検出器に対して one-to-many ラベル割り当てとして追加する訓練スキームで、推論コストを増やすことなくエンコーダの監督とデコーダのアテンションを豊かにし、COCO と LVIS で最先端の結果を達成します。
In this paper, we provide the observation that too few queries assigned as positive samples in DETR with one-to-one set matching leads to sparse supervision on the encoder's output which considerably hurt the discriminative feature learning of the encoder and vice visa for attention learning in the decoder. To alleviate this, we present a novel collaborative hybrid assignments training scheme, namely $\mathcal{C}$o-DETR, to learn more efficient and effective DETR-based detectors from versatile label assignment manners. This new training scheme can easily enhance the encoder's learning ability in end-to-end detectors by training the multiple parallel auxiliary heads supervised by one-to-many label assignments such as ATSS and Faster RCNN. In addition, we conduct extra customized positive queries by extracting the positive coordinates from these auxiliary heads to improve the training efficiency of positive samples in the decoder. In inference, these auxiliary heads are discarded and thus our method introduces no additional parameters and computational cost to the original detector while requiring no hand-crafted non-maximum suppression (NMS). We conduct extensive experiments to evaluate the effectiveness of the proposed approach on DETR variants, including DAB-DETR, Deformable-DETR, and DINO-Deformable-DETR. The state-of-the-art DINO-Deformable-DETR with Swin-L can be improved from 58.5% to 59.5% AP on COCO val. Surprisingly, incorporated with ViT-L backbone, we achieve 66.0% AP on COCO test-dev and 67.9% AP on LVIS val, outperforming previous methods by clear margins with much fewer model sizes. Codes are available at \url{https://github.com/Sense-X/Co-DETR}.
研究の動機と目的
- 一対一の DETR セットマッチングの限界、特にエンコーダの監督の希薄さとデコーダのアテンションの弱さを動機づけて分析する。
- 補助ヘッドによる one-to-many ラベル割り当てを用いてエンコーダの監督を豊かにする協調的ハイブリッド割り当て訓練(Co-DETR)方式を提案する。
- 補助ヘッドを介してカスタマイズされた正のクエリを生成し、パラメータを共有することでデコーダ訓練を強化する。
- Co-DETR が推論オーバーヘッドを増やすことなく、さまざまな DETR バリアントの収束と精度を改善することを示す。
提案手法
- versatile な one-to-many ラベル割り当てで監督される K 個の補助ヘッドを導入する(例:ATSS、Faster R-CNN、RetinaNet、FCOS)。
- エンコーダ出力から特徴ピラミッドを構築し、複数のスケールで補助ヘッドへ供給する。
- 補助ヘッドごとに割り当てられた正例/負例を用いて損失の総和として enc 損失を計算する。
- 補助ヘッドの正の座標からカスタマイズされた正のクエリを生成し、元のデコーダーアーキテクチャを変更することなくデコーダ訓練を豊かにする。
- メインのワン・トゥ・ワン DETR 損失と補助ヘッド損失をバランス係数で結合したグローバル Objective で訓練する。
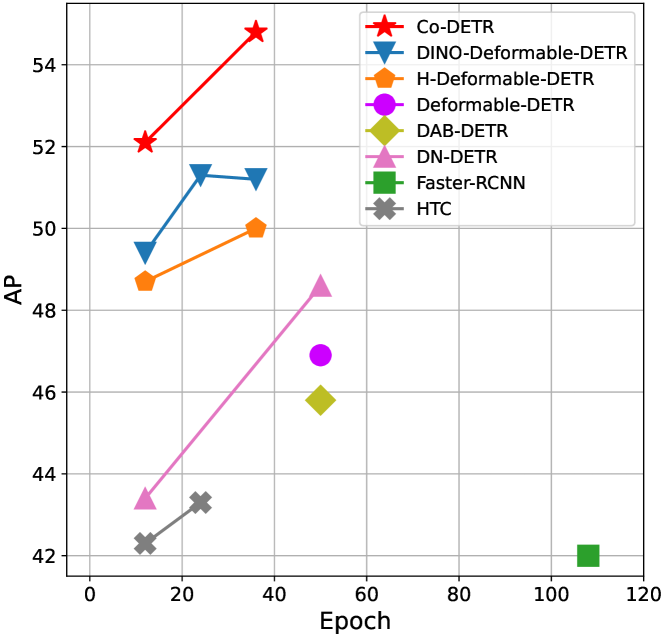
実験結果
リサーチクエスチョン
- RQ1補助ヘッドを one-to-many 割り当てで導入すると、DETR バリアントのエンコーダの識別性と特徴学習にどのような影響があるか?
- RQ2補助ヘッドからのカスタマイズされた正のクエリは、推論コストを増やすことなくデコーダのクロスアテンション学習を改善できるか?
- RQ3Co-DETR を様々なバックボーン(例:Deformable-DETR、DINO-Deformable-DETR、Swin-L バックボーン)に適用した場合の COCO および LVIS における性能向上はどの程度か?
- RQ4補助ヘッドはどのように相互作用し、安定した訓練のための限界(最適なヘッド数など)はどこにあるか?
主な発見
- Co-DETR は DETR バリアント全体で有意な AP 増加をもたらし、例として Deformable-DETR は 5.8 AP(12 エポック)および 3.2 AP(36 エポック)の改善を示す。
- DINO-Deformable-DETR が Swin-L を用いた場合、COCO val で 58.5 から 59.5 AP へ改善する。
- ViT-L バックボーンでは、Co-DETR は COCO test-dev で 66.0 AP、LVIS val で 67.9 AP を達成し、より小さいモデルで従来手法を上回る。
- COCO val で、ViT-L を用いた Co-DETR は 65.9 AP(val)/ 66.0 AP(test-dev)を達成。LVIS の結果には 56.9 AP(val)/ 62.3 AP(minival)が含まれる。
- Co-DETR は収束を速め、推論コストを追加しない状態を維持できる。補助ヘッドはテスト時に廃棄されるため。
- 大規模バックボーン(Objects365 で事前学習した ViT-L)での場合、Co-DETR は COCO test-dev で 66.0 AP、LVIS minival で 71.9 AP という新記録を樹立(重いテスト時拡張を用いず)。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。