[論文レビュー] Device Placement Optimization with Reinforcement Learning
本論文は、REINFORCEで最適化されたシーケンスツーシーケンス方策を用いてニューラルネットの TensorFlow デバイス配置を最適化することを学習し、手作業のヒューリスティクスや Scotch ベースラインより高速な配置を実現する。
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.
研究の動機と目的
- heterogeneous ハードウェアでのデバイス配置を改善することによるトレーニング/推論コストの削減を動機づける。
- グラフ操作をデバイスへ割り当て、実行時間を最小化する learned strategy を提案する。
- 人間設計の配置や従来のグラフ分割法に対して、複数モデルで改善を示す。
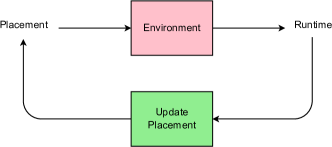
提案手法
- TF グラフ操作に対するポリシー π(P|G;θ) を用いた離散最適化としてデバイス配置をモデル化する。
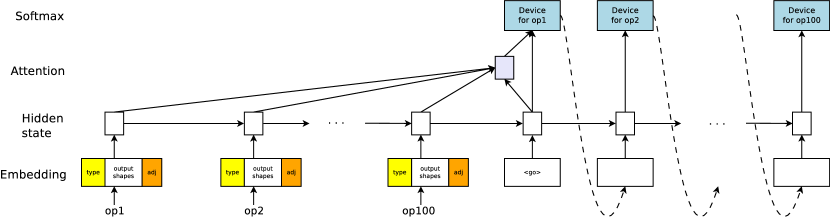
- シーケンスツーシーケンスモデル(アテンションあり)を用いて、グラフ内の各操作に対するデバイスを予測する。
- 報酬信号として R(P)=sqrt(r(P)) を用い、移動平均ベースラインとともに policy gradients(REINFORCE)で訓練する。
- シーケンス長を削減し大規模グラフを管理するために共置化グループを組み込む。
- 複数のコントローラとワーカーを用いた非同期分散訓練を実装し、配置をサンプル・評価する。
- 実機ハードウェア上で配置を実行して実行時間を測定し、それを報酬として用いる。
実験結果
リサーチクエスチョン
- RQ1TF グラフ上のデバイス配置において、 learned policy は手作業ベースおよび Scotch ベースラインを上回るか?
- RQ2Inception-V3、NMT、RNNLM など異なるモデルで、 learned placement が活用する計算と通信のトレードオフはどのようになるか?
- RQ3 RL ベースの配置を用いた場合と専門家設計の配置を比較したとき、エンドツーエンドの訓練時間とステップあたりの待機時間はどう変化するか?
主な発見
| Model | Single-CPU | Single-GPU | #GPUs | Scotch | MinCut | Expert | RL-based | Speedup |
|---|---|---|---|---|---|---|---|---|
| RNNLM | 6.89 | 1.57 | 2 | 13.43 | 11.94 | 3.81 | 1.57 | 0.0% |
| NMT | 10.72 | OOM | 2 | 14.19 | 11.54 | 4.99 | 4.04 | 23.5% |
| Inception-V3 | 26.21 | 4.60 | 2 | 25.24 | 22.88 | 11.22 | 4.60 | 0.0% |
- RL 配置は、複数のモデルで手作業ベースおよび Scotch を上回る非自明な構成を見つける。
- RL 配置による単一ステップの実行時間は、ベースラインより最大で 3.5x高速。
- RL ベースの配置を用いたエンドツーエンドの訓練は、NMT で約 28%、Inception-V3 で約 20% の訓練高速化を実現。
- NMT では、RL 配置がデバイス間の計算負荷を専門家配置より均衡させ、逆伝播中のボトルネックを減らす。
- Inception-V3 では、RL 配置がパラメータを消費者と共置してデバイス間データ転送を削減し、マルチ GPU 設定下での per-step 時間を速くする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。