[論文レビュー] DialogueLLM: Context and Emotion Knowledge-Tuned Large Language Models for Emotion Recognition in Conversations
DialogueLLM は emotion と context knowledge を用いて open-source LLaMA 2-7B を微調整し、マルチモーダル(テキスト+動画)指示データを使用して会話における感情認識の最先端を達成し、ゼロショットおよびfew-shot分析を含む。
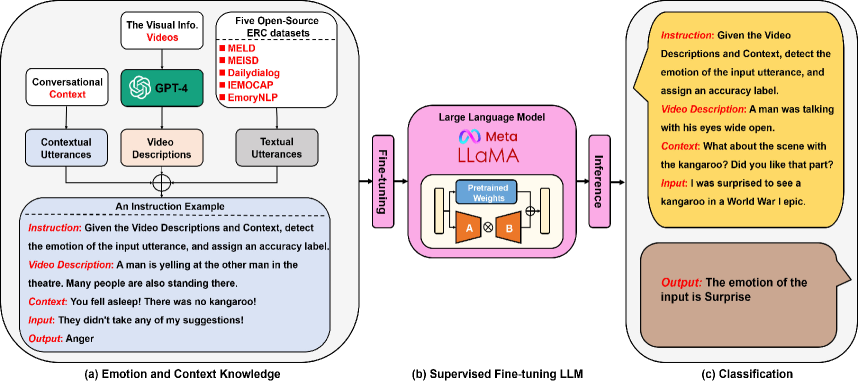
Large language models (LLMs) and their variants have shown extraordinary efficacy across numerous downstream natural language processing (NLP) tasks, which has presented a new vision for the development of NLP. Despite their remarkable performance in natural language generating (NLG), LLMs lack a distinct focus on the emotion understanding domain. As a result, using LLMs for emotion recognition may lead to suboptimal and inadequate precision. Another limitation of LLMs is that they are typical trained without leveraging multi-modal information. To overcome these limitations, we propose DialogueLLM, a context and emotion knowledge tuned LLM that is obtained by fine-tuning LLaMA models with 13,638 multi-modal (i.e., texts and videos) emotional dialogues. The visual information is considered as the supplementary knowledge to construct high-quality instructions. We offer a comprehensive evaluation of our proposed model on three benchmarking emotion recognition in conversations (ERC) datasets and compare the results against the SOTA baselines and other SOTA LLMs. Additionally, DialogueLLM-7B can be easily trained using LoRA on a 40GB A100 GPU in 5 hours, facilitating reproducibility for other researchers.
研究の動機と目的
- 一般的なLLMを超えた会話(ERC)における感情理解の推進。
- 感情と文脈知識を調整したLLMを提案し、ERCの精度を向上させる。
- 高品質な指示を構築するためにマルチモーダル(テキストと動画)の情報を活用する。
- 複数のERCベンチマークから指示チューニング用データセットを作成・活用して訓練を導く。
- 入手可能なハードウェアでLoRAベースの微調整を用いて再現性を示す。
提案手法
- ベースモデルとして LLaMA 2-7B を用い、感情知識の指示に対して LoRA で微調整する。
- 動画由来の説明を補足知識として用い、MELD、IEMOCAP、EmoryNLP から指示データセットを構築する。
- ERC をプロンプトに対して感情ラベルを出力する条件付き生成タスクとして扱う。
- 文脈的発話と動画説明をプロンプトに組み込み、感情分類を導く。
- 感情固有のタスクにモデルを合わせるため、2,411 ダイアログにわたる 24,304 発話に対して監視付き指示チューニングを適用する。

実験結果
リサーチクエスチョン
- RQ1感情特化型のLLM(DialogueLLM)は ERC タスクに対して有効か?
- RQ2対話の文脈とマルチモーダル情報を取り入れることで ERC の性能は向上するか?
- RQ3ゼロショットおよび few-shot 設定で DialogueLLM は ERC に対して強力なインコンテキスト学習能力を示せるか?
主な発見
- DialogueLLM は 3 つの ERC データセットで最先端の性能を達成し、15 のベースラインを上回った。
- MELD で、DialogueLLM は accuracy 71.96%、weighted F1 score 71.81% を達成。
- IEMOCAP で、accuracy 70.62%、weighted F1 score 69.93% を達成。
- EmoryNLP で、accuracy 41.88%、weighted F1 score 40.05% を達成。
- DialogueLLM は three ERC タスクでそれぞれのベースラインに対して改善幅 5.36%、1.03%、1.5% を示す。
- アブレーション研究は、文脈、LoRA、および動画由来の説明がそれぞれ性能に寄与することを確認し、いずれかの要素を削除すると顕著な低下が生じる。
- ゼロショットおよびワンショットのプロンプトは競争力のある結果を生み出し、ショット数が増えるにつれて利得は限定的であり、安定しているが少数ショットには敏感な挙動を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。