[論文レビュー] DiffDA: a Diffusion Model for Weather-scale Data Assimilation
DiffDAは、GraphCastを基盤とするノイズ除去拡散モデルを用いて、予測状態とまばらな観測を組み合わせて高分解能の大気データを同化し、リアルタイムに近い再分析と予報準備済みの初期条件を実現する。最大24時間のリードタイム損失。
The generation of initial conditions via accurate data assimilation is crucial for weather forecasting and climate modeling. We propose DiffDA as a denoising diffusion model capable of assimilating atmospheric variables using predicted states and sparse observations. Acknowledging the similarity between a weather forecast model and a denoising diffusion model dedicated to weather applications, we adapt the pretrained GraphCast neural network as the backbone of the diffusion model. Through experiments based on simulated observations from the ERA5 reanalysis dataset, our method can produce assimilated global atmospheric data consistent with observations at 0.25 deg (~30km) resolution globally. This marks the highest resolution achieved by ML data assimilation models. The experiments also show that the initial conditions assimilated from sparse observations (less than 0.96% of gridded data) and 48-hour forecast can be used for forecast models with a loss of lead time of at most 24 hours compared to initial conditions from state-of-the-art data assimilation in ERA5. This enables the application of the method to real-world applications, such as creating reanalysis datasets with autoregressive data assimilation.
研究の動機と目的
- 高分解能の大気データを扱える機械学習ベースのデータ同化手法を示す。
- 拡散ベースの同化器のバックボーンとして、事前学習済みの気象予報モデルを組み込む。
- トレーニングと推論時に予測状態での条件付けを示し、推論時にはまばらな観測での条件付けを行う。
- 原理的にはERA5と互換性のある再分析データを生成する自己回帰的データ同化を可能にする。
提案手法
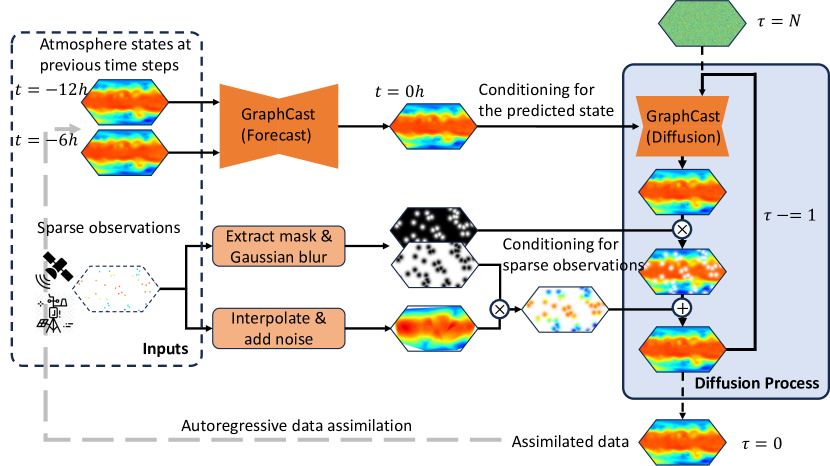
- GraphCastをデータ同化用のノイズ除去拡散モデルとして適応させる。
- 拡散モデルを、訓練時および推論時に予測状態 x̂ で条件付ける。
- 推論時には、ソフトマスクと補間戦略を用いて、まばらな観測で拡散過程を条件付ける。
- 観測が利用できない場合に後処理を可能にするため、2段階の条件付けアプローチを用いる。
- 拡散目的関数で p(x^0 | x̂) を学習し、逆拡散ステップでサンプリングする。
- GraphCast以外の代替予報バックボーンを組み込む柔軟性を提供する。

実験結果
リサーチクエスチョン
- RQ1予測状態とまばらな観測の両方を条件付けした拡散ベースのモデルは高分解能の大気場を同化できるか?
- RQ2訓練時および推論時の予測状態での条件付けは、同化結果を真値に近づけるか?
- RQ3このアプローチは再分析風データを生成し、許容されるリードタイム損失で予報準備性を維持できるか?
- RQ4自己回帰データ同化と観測量の異なる量で手法はどう性能を示すか?
主な発見
- より多くの観測が用いられると、同化データは真値に収束する。
- 予報モデルの入力として使用した場合、同化データを用いた48時間予測誤差は、真値初期条件を使用する場合と比較してリードタイム損失が最大24時間となる。
- この手法は自己回帰的な同化サイクルで再分析風データを生成することを可能にする。
- 訓練時および推論時の予測状態での条件付けは、推論時に観測がなくても後処理能力を提供する。
- 観測に対するソフトマスキング戦略は、ハードマスクより条件付けの有効性を高める。
- GraphCastをバックボーンとして、13の鉛直レベルを持つ0.25度解像度へ拡張できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。