[論文レビュー] DiffFace: Diffusion-based Face Swapping with Facial Guidance
DiffFaceはID conditioningと事前学習済み専門家による顔面ガイダンス、およびターゲット保持ブレンディングを備え、再学習なしでソースのアイデンティティを転送しつつターゲット属性を維持する拡散モデルベースの顔スワップフレームワークを提案します。
In this paper, we propose a diffusion-based face swapping framework for the first time, called DiffFace, composed of training ID conditional DDPM, sampling with facial guidance, and a target-preserving blending. In specific, in the training process, the ID conditional DDPM is trained to generate face images with the desired identity. In the sampling process, we use the off-the-shelf facial expert models to make the model transfer source identity while preserving target attributes faithfully. During this process, to preserve the background of the target image and obtain the desired face swapping result, we additionally propose a target-preserving blending strategy. It helps our model to keep the attributes of the target face from noise while transferring the source facial identity. In addition, without any re-training, our model can flexibly apply additional facial guidance and adaptively control the ID-attributes trade-off to achieve the desired results. To the best of our knowledge, this is the first approach that applies the diffusion model in face swapping task. Compared with previous GAN-based approaches, by taking advantage of the diffusion model for the face swapping task, DiffFace achieves better benefits such as training stability, high fidelity, diversity of the samples, and controllability. Extensive experiments show that our DiffFace is comparable or superior to the state-of-the-art methods on several standard face swapping benchmarks.
研究の動機と目的
- ターゲット属性を保持しつつソースのアイデンティティを転送するための堅牢で高忠実度な顔スワップを動機づける。
- 拡散モデルを活用して安定した訓練とアイデンティティ指向の合成を可制御化する。
- 再学習なしでサンプリング時に外部の顔専門家ガイダンス(アイデンティティ、パーシング、視線)を組み込む。
- ターゲットの背景と構造を維持するターゲット保持ブレンディング戦略を開発する。
提案手法
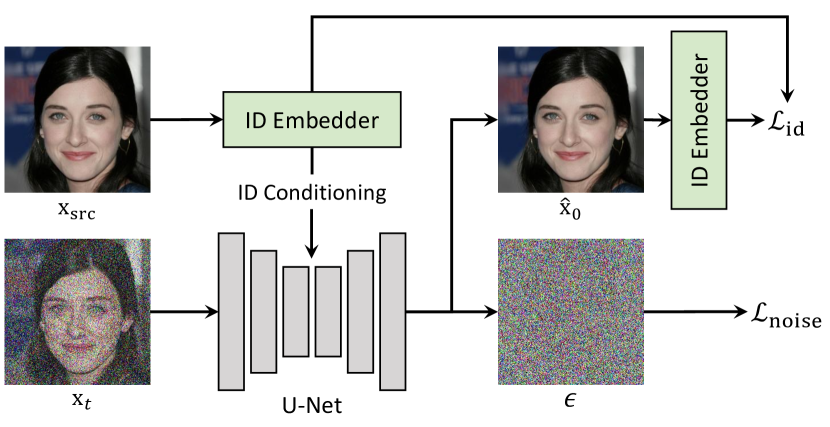
- ソースアイデンティティを生成するID条件付きDDPMを訓練する。
- アイデンティティ埋め込みとアイデンティティ類似性損失を介して拡散過程にアイデンティティ特徴を組み込む。
- サンプリング時に事前学習済みの専門家(アイデンティティ埋め込み器、顔パーサー、視線推定器)を用いてガイダンスを適用し、属性を維持しつつアイデンティティを転送する。
- スワップ中にターゲットの背景と構造を保持するため、マスク強度を徐々に増加させるターゲット保持ブレンディング戦略を用いる。
- 再訓練なしでテスト時にアイデンティティと属性のトレードオフを制御可能にする。
- 拡散ステップにわたって進化するターゲット保持ブレンディングマスクM_tを活用して、スワップ画像とターゲット画像をブレンドする。
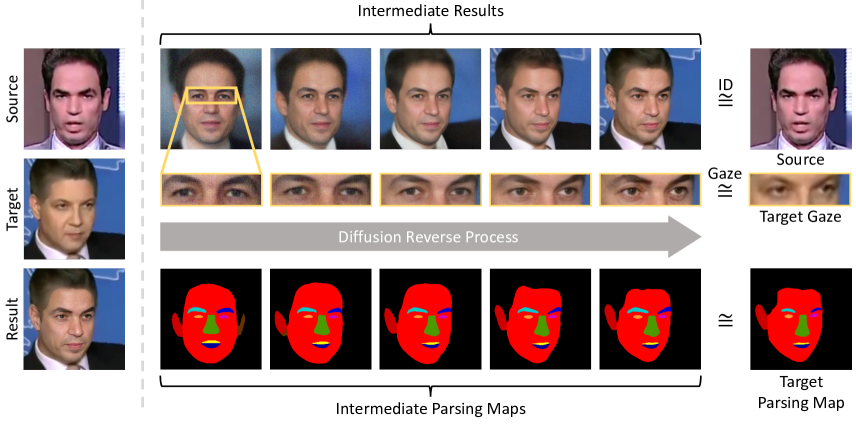
実験結果
リサーチクエスチョン
- RQ1拡散モデルを条件付けて、顔スワップにおいてソースのアイデンティティをターゲット属性を保ちながら信頼して転送できるのか。
- RQ2外部の顔専門家モデルが拡散サンプリングをどのように指向し、再訓練なしでアイデンティティ・意味情報・視線を制御できるのか。
- RQ3ターゲット保持ブレンディングはターゲットの背景を維持しつつアイデンティティを転送できるのか、そしてトレードオフを適応的に制御できるのか。
- RQ4DiffFaceはFF++において最先端のGANベースの顔スワップ手法と競合する、または優れているのか。
- RQ5ID Conditional DDPM、顔ガイダンス、ターゲットブレンディングの寄与についてのアブレーションは何を示すのか。
主な発見
| モデル | Arc↑ | Arc-R↑ | Cos↑ | Cos-R↑ | Expr↓ | Pose↓ | Shp↓ |
|---|---|---|---|---|---|---|---|
| SimSwap | 0.597 | 0.756 | 0.033 | 0.0005 | 0.0256 | 0.0005 | 0.0256 |
| HifiFace | 0.575 | 0.816 | 0.565 | 0.792 | 0.048 | 0.0007 | 0.0299 |
| InfoSwap | 0.570 | 0.841 | 0.052 | 0.0010 | 0.0360 | 0.0010 | 0.0360 |
| MegaFS | 0.343 | 0.553 | 0.046 | 0.0024 | 0.0299 | 0.0024 | 0.0299 |
| FaceShifter | 0.534 | 0.657 | 0.061 | 0.0013 | 0.0235 | 0.0013 | 0.0235 |
| DeepFakes | 0.443 | 0.686 | 0.078 | 0.0022 | 0.0314 | 0.0022 | 0.0314 |
| (Cos) DiffFace( hat{T}=40 ) | 0.620 | 0.859 | - | - | 0.044 | 0.0009 | 0.0269 |
| (Arc) DiffFace( hat{T}=40 ) | - | - | 0.602 | 0.816 | 0.043 | 0.0008 | 0.0283 |
| (Cos) DiffFace( hat{T}=50 ) | 0.634 | 0.888 | - | - | 0.050 | 0.0011 | 0.0303 |
| (Arc) DiffFace( hat{T}=50 ) | - | - | 0.603 | 0.816 | 0.049 | 0.0009 | 0.0311 |
- DiffFaceは最も高いアイデンティティ類似度スコア(Arc↑、Arc-R↑、Cos↑、Cos-R↑)と、対象アイデンティティの除去能力でベースラインと比較して優位を示す。
- 拡散ベースのアプローチはアイデンティティと属性の制御を堅牢に提供し、FF++における主要指標でGANベース手法を上回る。
- アブレーションによりID Conditional DDPMとアイデンティティガイダンスが強いアイデンティティ転送に必須であり、ターゲット保持ブレンディングはアイデンティティとターゲット構造のトレードオフを制御可能にすることが示された。
- 視線と意味ガイダンスはスワップ時にターゲットの視線と顔の構造を保持するのに寄与する。
- アイデンティティと形状のトレードオフはブレンディングタイミングパラメータ hat{T} とガイダンス重みを調整することで調整可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。