[論文レビュー] DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
本論文は Sketch-Guided Latent Diffusion Model (SGLDM) を提案し、モノクロスケッチを高品質な顔画像へ変換する。Multi-Auto-Encoder のスケッチ条件付けと Stochastic Region Abstraction データ拡張を用い、スケッチの一貫性と編集可能性を高く示す。
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
研究の動機と目的
- モノクロスケッチから高品質な顔画像を合成する必要性を、幾何学的正確性を保持しつつ喚起する。
- 潜在拡散モデルを用いた画像間翻訳において、スケッチのみを条件付けとして活用するフレームワークを提案する。
- 領域ごとのスケッチエンコーディングと二段階の訓練プロセスを通じて局所ジオメトリとディテールを保持する。
- データ拡張(SRA)を介して異なるスケッチ抽象化レベルに対する頑健性を高める。
- スケッチ-to-face タスクにおいて、最先端手法と比較して高い忠実度とスケッチ一貫性を示す。
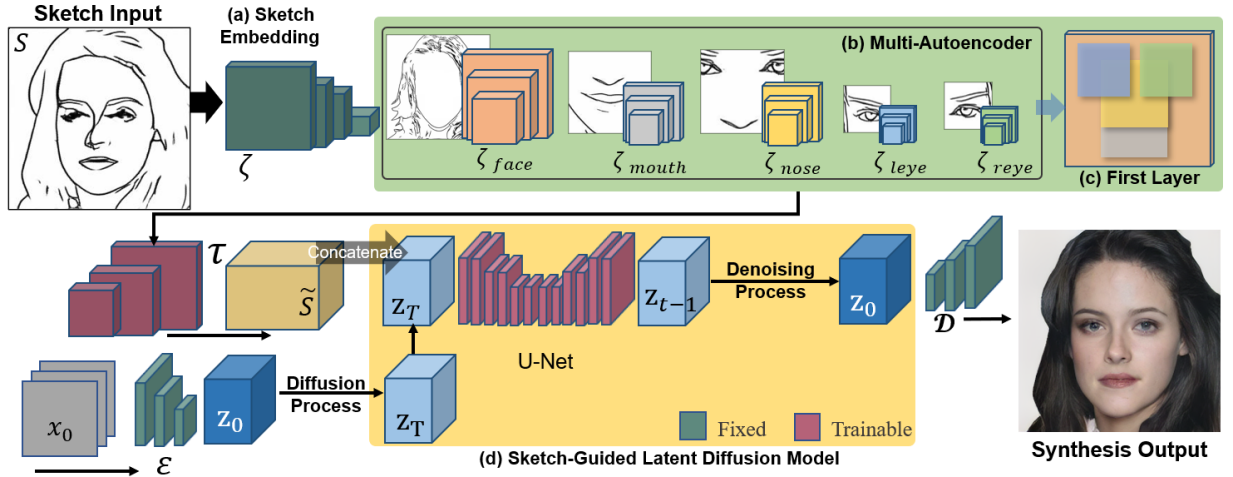
提案手法
- 効率的な高品質合成のためのバックボーンとして Latent Diffusion Model (LDM) を使用する。
- 顔の異なる領域からのスケッチを潜在特徴マップへエンコードする Multi-Auto-Encoder (AE) を導入する。
- 二段階の訓練方式を採用する:まずスケッチ埋め込み(Multi-AE)を事前訓練し、次に条件付き潜在マップを用いて SGLDM を訓練する。
- latent space の denoising U-Net に対してスケッチ条件付きマップを提供する条件付けモジュールを定義する。
- 様々な抽象度レベルのスケッチを拡張するために、Stochastic Region Abstraction (SRA) を適用する。
- 頑健性を高めるために、条件付け特徴にマスキング戦略を任意で用いる(MAE に触発)。
![Figure 2 : An example of implementing a LDM-based model, stable diffusion [ 17 ] with pre-trained weights. Although we inputted a single sketch (left) and texts (e.g., “ a face photo ” or “ a portrait ”), the generated results are not colored images but monochrome sketches, and do not reproduce the](https://ar5iv.labs.arxiv.org/html/2302.06908/assets/figs/png/ldm_fail.png)
実験結果
リサーチクエスチョン
- RQ1スケッチのみを入力とするモデルは、入力スケッチの幾何を保持しつつ高品質でフォトリアルな顔画像を合成できるか?
- RQ2二段階訓練と領域を意識したスケッチ条件付けは、結合訓練より忠実度と一貫性を向上させるか?
- RQ3Stochastic Region Abstraction によるデータ拡張は、スケッチ抽象度レベルへの頑健性にどのように影響するか?
- RQ4品質と入力忠実度の観点で、SGLDMは最先端のスケッチ-to-face 手法とどう比較されるか?
主な発見
| Method | FID (Low) | LPIPS (Low) | REC (Low) | FID (Mid) | LPIPS (Mid) | REC (Mid) | FID (High) | LPIPS (High) | REC (High) |
|---|---|---|---|---|---|---|---|---|---|
| Pix2pix | 53.67 | 0.20 | 0.54 | 59.46 | 0.23 | 0.50 | 63.45 | 0.28 | 0.51 |
| Pix2pixHD | 51.23 | 0.18 | 0.62 | 53.71 | 0.22 | 0.55 | 60.23 | 0.25 | 0.53 |
| Psp | 83.48 | 0.29 | 0.37 | 83.32 | 0.26 | 0.45 | 85.54 | 0.28 | 0.48 |
| SGLDM joint training | 46.28 | 0.20 | 0.65 | 48.62 | 0.23 | 0.54 | 50.33 | 0.26 | 0.51 |
| SGLDM w/o SRA | 38.57 | 0.17 | 0.77 | 48.87 | 0.26 | 0.51 | 57.76 | 0.29 | 0.48 |
| Ours (SGLDM) | 43.58 | 0.22 | 0.71 | 45.46 | 0.24 | 0.59 | 46.83 | 0.24 | 0.57 |
- SGLDM は、スケッチ-to-face タスクにおいて競合手法よりも入力整合性と視覚的忠実度を高く達成する。
- 別個に事前訓練された Multi-AE 条件付けモジュールを伴う 2 段階の訓練戦略は、スケッチと顔分布間のドメインマッピングを改善する。
- SRA データ拡張は、異なる抽象度のスケッチに対する頑健性を高める。
- 定量指標(FID, LPIPS, REC)は、低・中・高の抽象度レベル全てで Pix2pix、Pix2pixHD、Psp より SGLDM を支持する。
- SGLDM は編集(表情、ヘアスタイル、アクセサリ)機能を示しつつ、編集下でもアイデンティティの安定性を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。