[論文レビュー] Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
DiffSegはStable Diffusionの自己注意を利用して訓練なしの無監督ゼロショットでセグメンテーションマスクを生成し、COCO-Stuff-27で最先端、Cityscapesで競合的な結果を出す。
Producing quality segmentation masks for images is a fundamental problem in computer vision. Recent research has explored large-scale supervised training to enable zero-shot segmentation on virtually any image style and unsupervised training to enable segmentation without dense annotations. However, constructing a model capable of segmenting anything in a zero-shot manner without any annotations is still challenging. In this paper, we propose to utilize the self-attention layers in stable diffusion models to achieve this goal because the pre-trained stable diffusion model has learned inherent concepts of objects within its attention layers. Specifically, we introduce a simple yet effective iterative merging process based on measuring KL divergence among attention maps to merge them into valid segmentation masks. The proposed method does not require any training or language dependency to extract quality segmentation for any images. On COCO-Stuff-27, our method surpasses the prior unsupervised zero-shot SOTA method by an absolute 26% in pixel accuracy and 17% in mean IoU. The project page is at \url{https://sites.google.com/view/diffseg/home}.
研究の動機と目的
- 事前学習済みStable Diffusionの自己注意に、アノテーションなしでのセグメンテーションに適したオブジェクト結合信号が含まれているかを調査する。
- 注意マップを訓練なしで一貫性のあるセグメンテーションマスクへ変換できる後処理パイプラインを開発する。
- 標準ベンチマークでゼロショット性能を示し、既存の無監督手法と比較する。
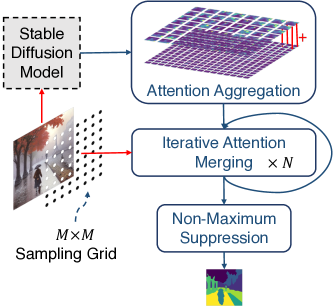
提案手法
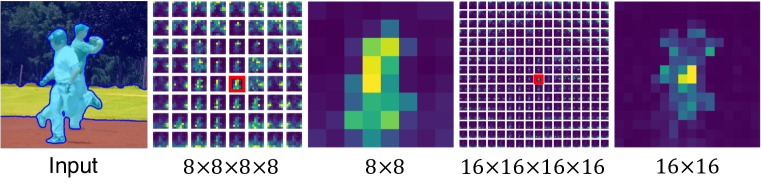
- 未条件 Stable Diffusion の実画像に対する自己注意テンソルを抽出する。
- 多解像度の注意マップを高解像度表現に集約する。
- 前提としてマスク数を事前指定せず、KLダイバージェンスを用いて注意マップを反復的に統合しオブジェクト提案マスクを形成する。
- 提案に対して非極大抑制を適用し、最終的なピクセル単位のセグメンテーションマスクを生成する。
- Ground-truthマスクとのハンガリー対応を用いてピクセル精度(ACC)と平均IoU(mIoU)で評価する。
実験結果
リサーチクエスチョン
- RQ1訓練やプロンプトなしでも、事前学習済みStable Diffusionモデルの自己注意はセグメンテーションに十分な内在的オブジェクト/グルーピング信号を示すか。
- RQ2単純な後処理を通じて、 unconditional拡散注意から高品質のセグメンテーションマスクを生成可能か。
- RQ3DiffSegはゼロショットのセグメンテーションベンチマークで、既存の無監督手法と比較してどう性能を示すか。
主な発見
| Model | LD | AX | UA | ACC | mIoU |
|---|---|---|---|---|---|
| IIC | ✗ | ✗ | ✓ | 21.8 | 6.7 |
| MDC | ✗ | ✗ | ✓ | 32.3 | 9.8 |
| PiCLE | ✗ | ✗ | ✓ | 48.1 | 13.8 |
| PiCLE+H | ✗ | ✗ | ✓ | 50.0 | 14.4 |
| STEGO | ✗ | ✗ | ✓ | 56.9 | 28.2 |
| ACSeg | ✓ | ✗ | ✓ | - | 28.1 |
| MaskCLIP | ✓ | ✗ | ✗ | 32.2 | 19.6 |
| ReCo | ✓ | ✓ | ✗ | 46.1 | 26.3 |
| K-Means-C | ✗ | ✗ | ✗ | 58.9 | 33.7 |
| K-Means-S | ✗ | ✗ | ✗ | 62.6 | 34.7 |
| Ours: DiffSeg (320) | ✗ | ✗ | ✗ | 72.5 | 43.0 |
| Ours: DiffSeg (512) | ✗ | ✗ | ✗ | 72.5 | 43.6 |
- DiffSegは無監督ゼロショットセグメンテーションでCOCO-Stuff-27における最先端の結果を達成し、ピクセル精度で従来のSOTAを26ポイント、mean IoUで17ポイント上回る。
- DiffSegは言語依存性や補助画像を必要とせず、それでもCOCO-Stuff-27で320×320および512×512解像度の両方で従来法を上回る。
- Cityscapesでは、DiffSegは従来のゼロショット手法と同等かそれ以上の性能を示し、特にクラスの粒度の点から小さな入力解像度を使用する場合に有利。
- 他の無監督ベースライン(例:K-Meansの派生)と比較して、DiffSegは事前にクラス数を決定する必要がなく、より安定し高品質なセグメンテーションを提供する。
- 手法は多様な画像スタイル(DomainNetのスケッチ、絵画、実世界の写真)への強い一般化能力を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。