[論文レビュー] Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
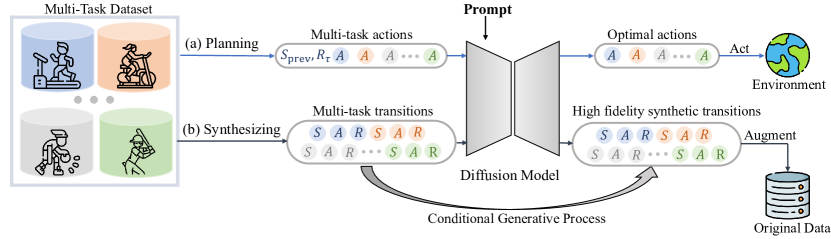
MTDiff は GPT をバックボーンとした拡散モデルとプロンプト学習を用いて、マルチタスクオフラインRLの計画とデータ合成の両方を可能にし、計画性能を向上させ、見たタスクと未見タスクのデータを拡張します。
Diffusion models have demonstrated highly-expressive generative capabilities in vision and NLP. Recent studies in reinforcement learning (RL) have shown that diffusion models are also powerful in modeling complex policies or trajectories in offline datasets. However, these works have been limited to single-task settings where a generalist agent capable of addressing multi-task predicaments is absent. In this paper, we aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution. Specifically, we propose Multi-Task Diffusion Model ( extsc{MTDiff}), a diffusion-based method that incorporates Transformer backbones and prompt learning for generative planning and data synthesis in multi-task offline settings. extsc{MTDiff} leverages vast amounts of knowledge available in multi-task data and performs implicit knowledge sharing among tasks. For generative planning, we find extsc{MTDiff} outperforms state-of-the-art algorithms across 50 tasks on Meta-World and 8 maps on Maze2D. For data synthesis, extsc{MTDiff} generates high-quality data for testing tasks given a single demonstration as a prompt, which enhances the low-quality datasets for even unseen tasks.
研究の動機と目的
- 多様なマルチタスクオフラインRLデータを扱える単一モデルの学習を動機づける。
- 拡散モデルが多モードのマルチタスク軌跡をモデル化できる方法を探る。
- 計画用(MTDiff-p)およびデータ合成用(MTDiff-s)のための、プロンプト条件付きのトランスフォーマーベースの拡散手法を開発する。
- MTDiff が未見タスクへ一般化でき、データ効率を向上させることを示す。
提案手法
- 拡散モデルを用いた条件付きデノイジング問題として、マルチタスク軌跡モデリングを定式化する。
- タスクプロンプトを用いて逐次軌跡をモデル化するため、GPT-2ベースのトランスフォーマー・バックボーンを使用する。
- 計画モード(MTDiff-p)では、プロンプトとリターンを条件付けて、分類子なしガイダンスを介して最適な行動系列を生成する。
- データ合成モード(MTDiff-s)では、タスクプロンプトを条件付けて遷移(状態、行動、報酬)を合成し、データ拡張を行う。
- デモンストレーションをワンホットIDではなくタスク条件づけプロンプトとして機能させる、柔軟なプロンプト方式を組み込む。
- デノイジング損失を最小化する拡散逆過程で訓練し、高い尤度系列のために低温サンプリングをオプションで適用する。
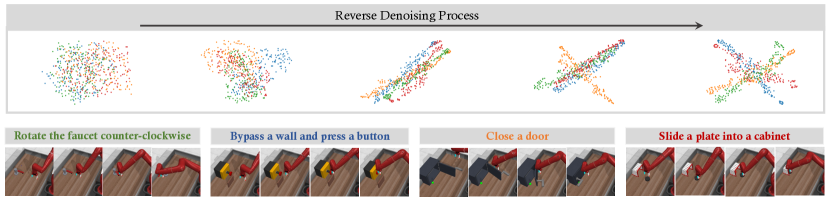
実験結果
リサーチクエスチョン
- RQ11つの拡散モデルが複数のオフラインRLタスクを学習し、一般化できるか?
- RQ2プロンプト条件付き拡散モデルは、ベースラインと比較してマルチタスクRLにおける計画品質を向上させるか?
- RQ3拡散ベースのデータ合成は、既知タスクと未知タスクのオフラインデータセットを効果的に拡張できるか?
- RQ4マルチタスク拡散は、単一タスク拡張法と比較してデータ効率と一般化にどのような利点をもたらすか?
主な発見
| 方法 | ほぼ最適 | 準最適 |
|---|---|---|
| CARE (Online) | 50.8±1.0 | - |
| PaCo (Online) | 57.3±1.3 | - |
| MTDT | 20.99±2.66 | 20.63±2.21 |
| PromptDT | 45.68±1.84 | 39.76±2.79 |
| MTBC | 60.39±0.86 | 34.53±1.25 |
| MTCQL | - | - |
| MTIQL | 56.21±1.39 | 43.28±0.90 |
| MTDiff-p (ours) | 59.53±1.12 | 48.67±1.32 |
| MTDiff-p-onehot (ours) | 61.32±0.89 | 48.94±0.95 |
- MTDiff-p は Meta-World MT50-rand および Maze2D のマルチタスク計画で最先端ベースラインを上回り、平均成功率をより高く達成した。
- MTDiff-s は高忠実度のマルチタスクデータを合成し、未見タスクを含む複数のタスクでオフラインRLの性能を向上させる。
- プロンプト付きの MTDiff-p は未知タスクへの少数ショット一般化を可能にし、適応テストでワンホットベースラインを上回る。
- MTDiff-s によって合成されたデータは、オフラインRLで単一タスクのデータ拡張手法(S4RL, RAD)を上回る実質的なポリシー改善をもたらす。
- マルチタスク訓練中のタスク数を増やすとデータ合成性能が徐々に向上し、マルチタスク知識共有が効果的であることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。