[論文レビュー] Diffusion Models for Open-Vocabulary Segmentation
OVDiff はテキストから画像への拡散モデルを用いて任意のカテゴリのサポート画像セットを生成し、複数のビジュアルプロトタイプ(前景と背景)を構築し、訓練なしで最近傍プロトタイプマッチングによって画像をセグメントします。ゼロショットのオープンボキャブラリセグメンテーション性能で強力な結果を達成し、決定をサポートセット領域にマッピングして説明可能性を提供します。
Open-vocabulary segmentation is the task of segmenting anything that can be named in an image. Recently, large-scale vision-language modelling has led to significant advances in open-vocabulary segmentation, but at the cost of gargantuan and increasing training and annotation efforts. Hence, we ask if it is possible to use existing foundation models to synthesise on-demand efficient segmentation algorithms for specific class sets, making them applicable in an open-vocabulary setting without the need to collect further data, annotations or perform training. To that end, we present OVDiff, a novel method that leverages generative text-to-image diffusion models for unsupervised open-vocabulary segmentation. OVDiff synthesises support image sets for arbitrary textual categories, creating for each a set of prototypes representative of both the category and its surrounding context (background). It relies solely on pre-trained components and outputs the synthesised segmenter directly, without training. Our approach shows strong performance on a range of benchmarks, obtaining a lead of more than 5% over prior work on PASCAL VOC.
研究の動機と目的
- オープンボキャブラリな意味的セグメンテーションを、ラベル付き訓練データなしで addressing。
- 各カテゴリの多様な外観と文脈をサンプリングするために拡散モデルを活用。
- 言語なしのプロトタイプで事前訓練済みのビジュアルバックボーンをグラウンディングして堅牢なセグメンテーションを実現。
- 前景と背景のプロトタイプを取り入れて物体と背景の分離と説明可能性を向上。
提案手法
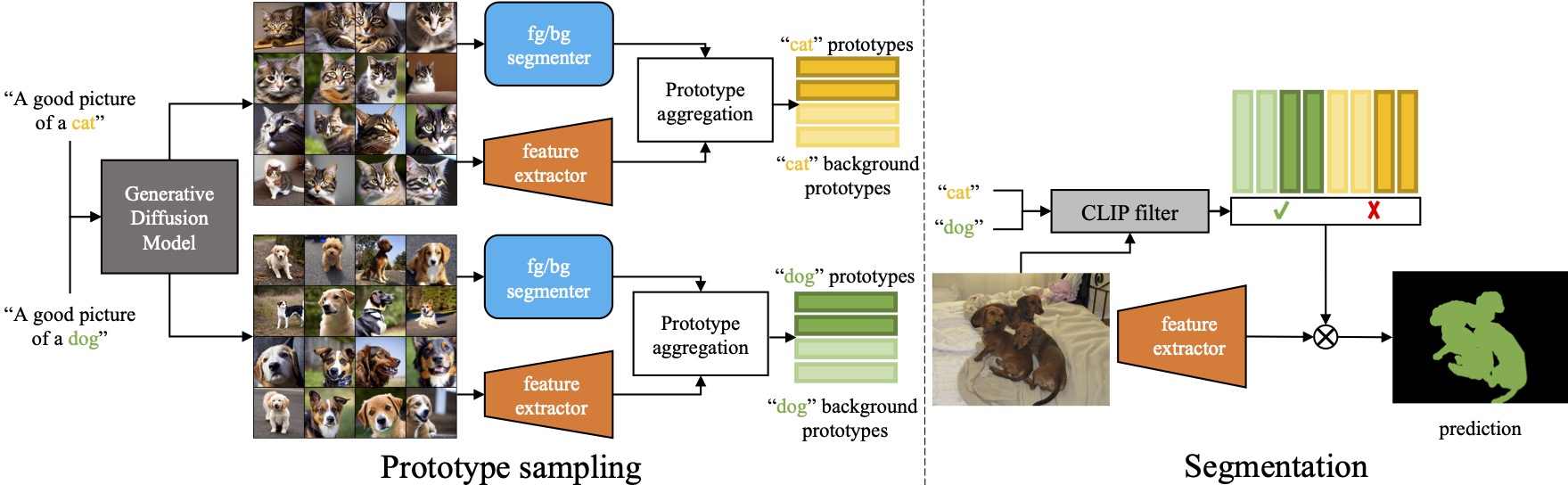
- Stable Diffusion を用いたテキストプロンプトでクエリごとにサポートセットを生成。
- 事前訓練済みビジュアルエンコーダと教師なしセグメンテーションを用いてサポート画像からクラスおよびインスタンスのプロトタイプを抽出。
- マスク付き特徴のクラスタリング(K-means)によって得られるパートレベルのセントロイドでプロトタイプを拡張。
- 前景および背景のプロトタイプを用いたオープンボキャブラリグラウンディングと、各ピクセルごとの単一のコサイン類似度ベースの分類器。
- CLIPベースのカテゴリ事前フィルタリングと stuffs/thing フィルタリングを適用して不適切なカテゴリを減らし、背景領域を処理。
- 各候補カテゴリ(背景クラスを含む)に対するプロトタイプセットとの最近傍マッチングでターゲット画像をセグメント。
実験結果
リサーチクエスチョン
- RQ1拡散生成サポートセットはファインチューニングなしでオープンボキャブラリセグメンテーションをグラウンディングできるか。
- RQ2複数のプロトタイプ(インスタンス、クラス、パート)と背景プロトタイプを用いるとセグメンテーション品質にどう影響するか。
- RQ3事前フィルタリングと stuffs/thing カテゴリのフィルタリングがオープンボキャブラリセグメンテーション性能に果たす役割は。
- RQ4OVDiff は標準的なオープンボキャブラリのベンチマーク(VOC、Context、Object)と異なる特徴抽出機でどう動作するか。
主な発見
| 方法 | VOC mIoU | Context mIoU | Object mIoU |
|---|---|---|---|
| OVDiff (Ours) | 67.1 ± 0.5 | 30.1 ± 0.2 | 34.8 ± 0.2 |
- OVDiff は強力なゼロショットのオープンボキャブラリセグメンテーションを達成し、VOC、Context、Object のベンチマークで従来手法を上回る。
- 背景プロトタイプとカテゴリ事前フィルタリングの活用は性能を大幅に向上させ、偽相関を減らす。
- SD、DINO、CLIP の特徴抽出機の組み合わせを用いた実験では最良の結果が得られ(例:VOC 63.6 の単一設定、アンサンブルで最大 67.0)。
- 前景・背景・パートレベルのプロトタイプはサポートセット領域に決定を結びつけることで、より細かなセグメンテーションと説明可能性を実現。
- この手法は訓練を伴わず、事前訓練済みコンポーネントと拡散ベースのサポートセット生成プロセスのみを用いる。
- サポートセットのサイズとともに性能がスケールし、クラスあたり約128サンプル程度で安定する。
![Figure 2 : Qualitative results . OVDiff in comparison to TCL [ 9 ] (+ PAMR) . OVDiff provides more accurate segmentations across a range objects and stuff classes with well defined object boundaries that separate from the background well. Last 2 columns show failure cases. Additional table and light](https://ar5iv.labs.arxiv.org/html/2306.09316/assets/figures/images/main_qual_figure.jpg)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。