[論文レビュー] Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
Diffusion-RWKV は RWKV バックボーンを拡散ベースの画像合成に適応させ、線形時間計算量と低い FLOPs を保ちながら、Transformer ベースの拡散モデルと競合する画像品質を実現します。
Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
研究の動機と目的
- 拡散ベースの画像生成タスクに RWKV アーキテクチャを適応させることを探る。
- 安定性とスケーラビリティを確保するための conditioning(条件付け)、スキップ接続、およびモデルスケーリングを調査する。
- 複数のデータセットに対してピクセル空間と潜在空間表現の実証ベースラインを提供する。
- 品質と効率の観点から CNN/Transformer 拡散ベースラインと性能を比較する。
提案手法
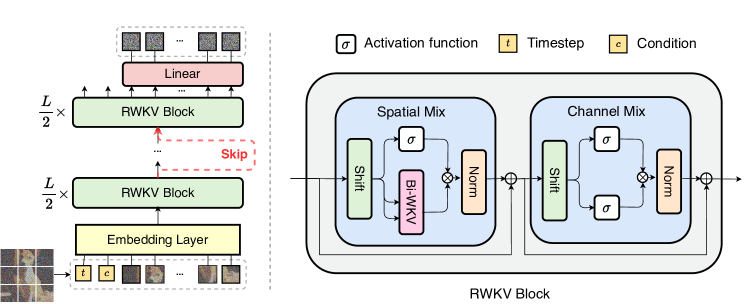
- Bi-RWKV をバックボーンとして、パッチ化された画像トークンを双方向・線形計算量の方式で処理する。
- 標準の自己注意を双方向 RWKV ベースの機構に置換し、四方向の空間移動とグローバルな線形注意を含める。
- 時間ステップ情報とクラス情報のために、インコンテキストトークン、adaLN、または adaLN-Zero による conditioning を組み込む。
- パッチ化して埋め込みを行い、位置埋め込みを用いてトークン列を形成する。
- 線形投影の前に、浅いブランチと深いブランチの状態を結合するスキップ接続フレームワークを適用する。
- DDPMベースのサンプリングのためにノイズと対角共分散を予測するLinear decoderを介して最終的な Bi-RWKV 出力をデコードする。
実験結果
リサーチクエスチョン
- RQ1RWKV様のバックボーンで構築された拡散モデルは、Transformerベースの拡散モデルと比較して高解像度の画像生成タスクでどのように性能を発揮しますか?
- RQ2どのアーキテクチャ上の選択肢(パッチサイズ、スキップ接続、 conditioning )が品質・速度・スケーラビリティのバランスを最も効果的に取れますか?
- RQ3Diffusion-RWKV は様々な解像度で、より低い FLOPs とメモリ使用量で競争力のある FID/IS を達成できますか?
- RQ4CIFAR-10、CelebA、ImageNet などのデータセットで、モデルスケーリング(深さ/幅)が性能と効率にどのように影響しますか?
主な発見
| Model | #Params | FID ↓ |
|---|---|---|
| DRWKV-S/2 | 39M | 3.03 |
| DRWKV-H/2 | 2.95 | 4.95 |
- Diffusion-RWKV は、同等の学習条件の下で CNN/Transformer 拡散モデルと同等またはそれ以上の FID 結果を達成します。
- 小さめのパッチサイズと長いスキップ結合は生成品質と学習効率を向上させます。
- AdaLN-Zero conditioning は、インコンテキスト conditioning よりも優れた FID 性能と効率を提供します。
- より大きな Bi-RWKV モデルは FLOPs 増加に伴いより良い FID を示し、DiT ベースラインに匹敵するスケーラブルな改善を示します。
- ImageNet 256x256 で、DRWKV-H/2 はいくつかの最先端モデルと比較して全体 FLOPs が低い状態で競争力のある FID を達成します。
- 512x512 では、DRWKV-H/2 は競争力を保ちつつ、計算負荷を低減しつつトップクラスの手法に近づきます。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。