[論文レビュー] DiffusionDet: Diffusion Model for Object Detection
DiffusionDetは物体検出をデノイズ拡散プロセスとして扱い、ランダムなボックスを物体ボックスへと精製する。これにより提案数を動的にし、競争力のある性能を持つ反復評価を実現する。
We propose DiffusionDet, a new framework that formulates object detection as a denoising diffusion process from noisy boxes to object boxes. During the training stage, object boxes diffuse from ground-truth boxes to random distribution, and the model learns to reverse this noising process. In inference, the model refines a set of randomly generated boxes to the output results in a progressive way. Our work possesses an appealing property of flexibility, which enables the dynamic number of boxes and iterative evaluation. The extensive experiments on the standard benchmarks show that DiffusionDet achieves favorable performance compared to previous well-established detectors. For example, DiffusionDet achieves 5.3 AP and 4.8 AP gains when evaluated with more boxes and iteration steps, under a zero-shot transfer setting from COCO to CrowdHuman. Our code is available at https://github.com/ShoufaChen/DiffusionDet.
研究の動機と目的
- 境界ボックスの空間に拡散を適用することで、より単純で学習可能なクエリ不要の物体検出器を動機づける。
- トレーニングと推論を切り離し、動的な提案数と反復的な洗練を実現する。
- COCO、CrowdHuman、LVIS のベンチマーク全体で競争力のある性能を示し、ゼロショット転送のシナリオも含む。
提案手法
- トレーニング時に、検出をグラウンドトゥルースボックスからノイジーなボックスへと拡散プロセスとして定式化する。
- ノイズを含む入力に条件付けてボックスを予測するため、画像エンコーダと6段階の検出ヘッドを用いる。
- グラウンドトゥルースボックスをパディングし、コサインスケジュールでガウスノイズを適用してトレーニングターゲットを作成する。
- 推論時にはランダムなボックスから始め、学習済み検出ヘッドと時刻条件付けにより反復的にデノイズする。
- 検出ヘッドをステップ間で再利用し、ボックスの更新とDDIMベースの更新を適用して反復評価を可能にする。
- 再学習なしで任意のボックス数とステップ数で評価できる柔軟性を許す。
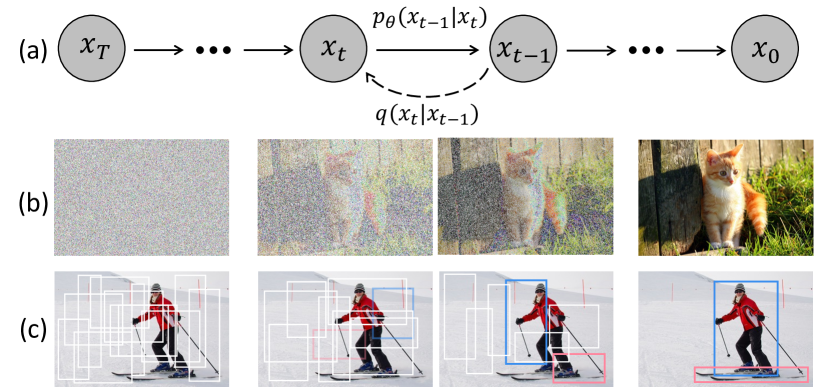
実験結果
リサーチクエスチョン
- RQ1物体検出を境界ボックス上のデノイジング拡散プロセスとして効果的に適用できるか?
- RQ2拡散ベースの検出器は再学習なしに、動的な提案数と反復的洗練をサポートするか?
- RQ3従来の検出器と比較して、標準およびゼロショット転送ベンチマーク(COCO、CrowdHuman、LVIS)でDiffusionDetはどの程度の性能を示すか?
主な発見
| Model | AP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|
| DiffusionDet (1 @ 300) | 45.8 | 64.1 | 50.4 | 27.6 | 48.7 | 62.2 |
| DiffusionDet (4 @ 300) | 42.0 | 55.8 | 44.9 | 34.8 | 40.9 | 46.4 |
| DiffusionDet (1 @ 500) | 46.3 | 64.8 | 50.7 | 28.6 | 49.0 | 62.1 |
| DiffusionDet (4 @ 500) | 46.8 | 65.3 | 51.8 | 29.6 | 49.3 | 62.2 |
| Swin-Base Backbone DiffusionDet (4 @ 300) | 42.0 | 55.8 | 44.9 | 34.8 | 40.9 | 46.4 |
- DiffusionDetはCOCOの結果で競争力を持つ、例えば1×300設定でAP 45.8、より多くのボックスやステップで改善(例: COCOで4×500時にAP 46.8)
- COCOからCrowdHumanへのゼロショット転送では、評価ボックスを300から2000へ、反復を1から4へ増やすことでAPがそれぞれ5.3、4.8の改善を得た。
- Swin-BaseバックボーンのDiffusionDetは1@300でCOCO valで52.5 APに達し、いくつかのベースラインを上回り、より多くのステップや他のバックボーンでさらなる改善。
- LVISの結果は、評価ステップを増やすとDiffusionDetが利得を示し、例えば4@300または4@500のバックボーンは1@300より高いAPを示し、特に大きなバックボーンで顕著。
- このモデルは再学習なしで動的なボックス数と反復評価をサポートし、固定クエリ検出器とは異なる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。