[論文レビュー] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct Preference Optimization (DPO) は、明示的な報酬モデリングや強化学習なしに、人間の好みから言語モデルの方針を直接最適化します。PPOベースのRLHFと同等またはそれ以上の整合性を達成し、実装と訓練がより簡単です。
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
研究の動機と目的
- 人間の好みを活用して、操縦可能で安全かつ整合のとれた大規模言語モデルの必要性を喚起する。
- 明示的な報酬モデリングやRLなしで、好みから直接方針を最適化する新しいパラダイムを提案する。
- パラメータ再階層化が閉形式の最適方針を生み出すことを示し、単純な分類損失を可能にする。
- 感情制御、要約、対話などのタスクで、DPOをPPOベースのRLHFと比較する。
- DPOの安定性、効率性、スケーラビリティを、最大6Bパラメータのモデルで実証する。
提案手法
- 最適方針を閉形式で抽出できる報酬モデルのパラメータ化を導入する(式4)。
- 報酬を r(x,y)=β log(π(y|x)/π_ref(y|x)) の再パラメータ化で表現し、方針出力に対するBradley-Terryベースの好み損失を導出する(式7)。
- 暗黙の報酬を用いた、好まれた/好まれなかったペアに対する2値交差エントロピー目的関数を定式化する(式7)。
- 崩壊を防ぐため、暗黙の報酬順序誤差で損失に重みを付ける(勾配形式を議論)。
- 実用的なDPOパイプラインを概説する:π_refからサンプルを取り、人間の好みを収集し、DPO損失で最適化する。
- Plackett-Luce/Bradley-Terryモデルの下で報酬ベースのRLと同等であること、そしてActor-Critic法に対する堅牢性の利点を示す理論特性を議論する。
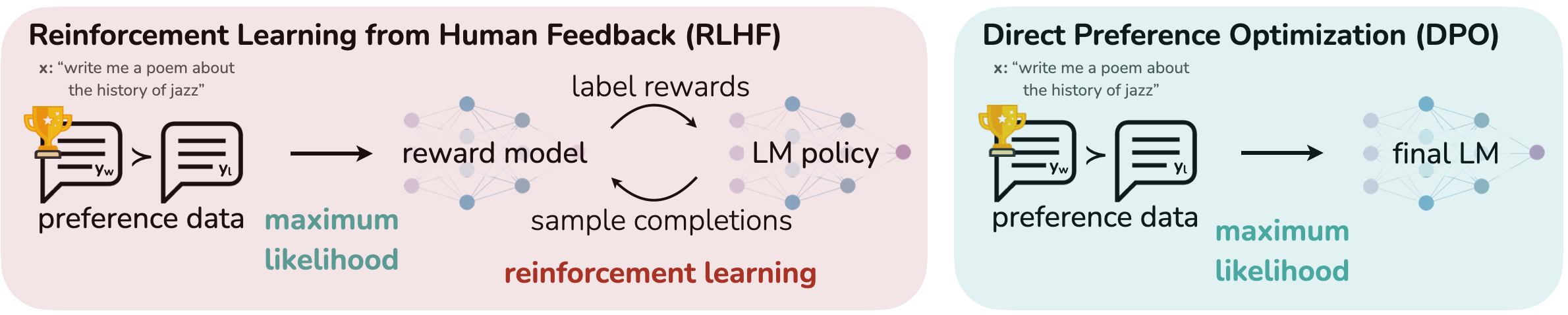
実験結果
リサーチクエスチョン
- RQ1人間の好みからの方針を直接最適化することは、タスク全体でPPOを用いたRLHFと同等またはそれを超えられるか。
- RQ2DPOの再パラメータ化は、明示的な報酬モデリングやRLループなしで最適方針を回復するか。
- RQ3感情制御、要約、対話における性能と安定性の点で、DPOはベースライン手法とどう比較されるか。
- RQ4DPOはPPOベースのRLHFよりもハイパーパラメータと温度に対してより効率的で頑健か。
- RQ5Plackett-Luce/Bradley-Terryモデルの下で、DPOの妥当性を裏付ける理論的保証は何か。
主な発見
- DPOは、与えられたKL制約のフロンティアで最高の報酬を達成し、感情フロンティアでPPOを凌駕する。
- 要約と対話タスクで、ハイパーパラメータ調整を少なくしてPPOベースのRLHFと同等以上を達成。
- サンプリング温度に対して堅牢で、強い性能へ速やかに収束する。
- 制御された感情設定では、PPOが正解報酬を手にしていてもDPOがPPOを上回る。
- 最大6BパラメータのLMで、単純で安定した訓練目的で競争力のある性能を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。