[論文レビュー] Direct speech-to-speech translation with a sequence-to-sequence model
この論文では、中間のテキスト表現を経由せずに、ある言語の音声を別の言語の音声に直接翻訳するエンドツーエンドのシーケンス・ツー・シーケンスモデル、Translatotronを提案する。訓練中は、学習の安定化を図るために、音声からテキストへの変換ヘッドを用いたマルチタスク学習を活用し、出力における元の話者の声を保全する音声転送を可能にする。性能はカスケード型システムに劣るが、エンドツーエンド学習と話者アイデンティティの保持を伴う直接的音声対音声翻訳の実現可能性を示している。
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.
研究の動機と目的
- 中間のテキスト表現を回避する直接的なエンドツーエンド音声対音声翻訳システムの開発を目的とする。
- 直接S2STにおいて、音声からテキストへの変換ヘッドを用いたマルチタスク学習が、エンドツーエンド推論を損なわずに学習を安定化させるかを調査すること。
- 翻訳出力音声における元の話者の声を保全する音声転送を可能とすること。
- 実世界のスペイン語→英語音声翻訳データセットを用いて、モデルの性能をカスケード型ベースラインと比較すること。
- 統合的なエンドツーエンドフレームワーク内で、クロスリンガルなプロソディと話者アイデンティティの転送を学習する可能性を検討すること。
提案手法
- モデルは、入力音声スペクトログラムと話者埋め込みを処理するため、アテンション機構を備えた8層の双方向LSTMエンコーダーをスタックして使用する。
- 2ストリームのデコーダーを採用:1つはターゲットスペクトログラムの生成に、もう1つは音素予測に使用。これにより、補助的変換タスクを伴うマルチタスク学習が可能になる。
- 話者エンコーダーは、参照発話から話者埋め込みを抽出し、訓練中に音声転送プロセスを条件づけるために使用する。
- 合成ターゲットと実際の音声データの組み合わせを用いてエンドツーエンドで学習し、翻訳、音素認識、音声転送のための損失関数を適用する。
- デコーダーを、元の音声とターゲット話者の話者埋め込みの両方に条件づけることで、元の話者の声で合成する音声転送を実現する。
- 予測されたスペクトログラムを波形出力に変換するため、音声生成器(ボコーダー)を用いて評価を実施する。
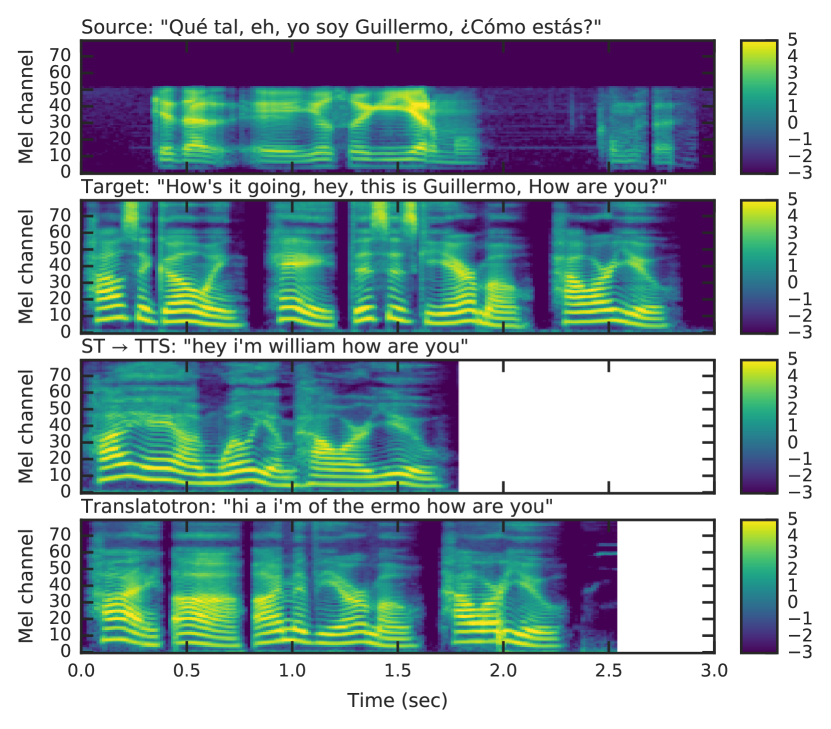
実験結果
リサーチクエスチョン
- RQ1エンドツーエンドのシーケンス・ツー・シーケンスモデルは、中間のテキスト表現に依存せずに、直接音声対音声翻訳を達成できるか?
- RQ2補助的な音声からテキストへの変換ヘッドを用いたマルチタスク学習は、直接S2STの学習をどの程度安定化させられるか?
- RQ3モデルは、翻訳出力音声において、元の話者の声をどの程度保全できるか?
- RQ4直接S2STモデルの性能は、音声対テキスト翻訳とテキスト対音声合成のカスケード型システムと比べてどうか?
- RQ5特にアライメントとデータ不足の観点から、直接S2STモデルを学習する際の主な課題は何か?
主な発見
- 元の話者の声に条件づけた場合、BLEUスコアは33.6を記録したが、真値のターゲット話者埋め込みを使用した場合の36.2に比べてわずかに低い。
- モデルの翻訳品質は、カスケード型ST+TTSベースラインに比べてわずかに劣っており、マルチタスク監視があるにもかかわらず、直接学習が依然として困難であることを示している。
- 元の話者に条件づけた場合の音声転送性能は、真値のターゲット話者を使用した場合(MOS類似度:3.30)と比較して顕著に低い(MOS類似度:1.85)ため、言語間で話者埋め込みの一般化が不十分であることが示唆された。
- ランダムなターゲット発話を用いて条件づけた場合、元の話者に条件づけた場合と同等のBLEU(35.4)とMOSスコア(3.08)が得られ、話者埋め込みからのコンテンツ漏洩は顕著でないことが示された。
- モデルは、同義語や固有名詞(例:「Guillermo」が「William」に翻訳されず「Guillermo」として保持される)を直接的に音声的に保全していることが示され、音声的保持へのバイアスがあることが示唆された。
- 補助的変換タスクを伴うエンドツーエンド学習により、限られた並列音声データでも直接S2STの学習が安定化することが、モデルによって実証された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。